Projet RODEO – Apprentissage profond robuste pour la robotique chirurgicale
Le projet ANR RODEO vise à transformer la robotique chirurgicale en intégrant les dernières avancées en intelligence artificielle (IA). Le cadre d’application est la chirurgie guidée par robot pour la colonne vertébrale, basée sur une plateforme chirurgicale disponible à l’ISIR.
Dans ce contexte, un bras robotique à 7 degrés de liberté (DoFs) est équipé de divers capteurs (position, vitesse, force, conductivité électrique, vibrations) et utilisé pendant des interventions chirurgicales, comme l’insertion de vis pédiculaires dans la colonne vertébrale. Cette plateforme robotique actuelle utilise un ensemble de lois de commande déjà implémentées (e.g., contrôle de position, de vitesse, de force) pour exécuter des tâches ou sous-tâches chirurgicales, comme le perçage d’une trajectoire préliminaire pour le placement des vis pédiculaires. Avant l’opération, un scanner 3D du patient est réalisé, permettant au chirurgien de définir la procédure médicale à suivre pendant la chirurgie.
Bien que des contrôleurs entièrement automatiques puissent être utilisés pour certaines sous-tâches sûres, les chirurgiens préfèrent un paradigme de co-manipulation pour les opérations sensibles, où les robots chirurgicaux assistent les procédures médicales. Dans ce cas, l’assistant robotique doit réagir fidèlement aux instructions du chirurgien tout en garantissant la sécurité du patient et du personnel médical, et s’adapter à l’environnement.
Le contexte
Bien que le système actuel de co-manipulation soit utile et réponde à certains besoins des chirurgiens, il peut être considérablement amélioré pour enrichir l’expérience chirurgicale. La plateforme chirurgicale de l’ISIR manque de modules de perception et d’enregistrement, et la procédure actuelle suppose que le patient ne bouge pas une fois positionné pour la chirurgie et que la colonne vertébrale est rigide. Cela peut rendre le transfert d’informations préopératoires complexe, imprécis et dangereux pour le patient. De plus, les contrôleurs actuels ne représentent pas certains phénomènes physiques complexes lors de la co-manipulation, comme les frottements du robot, les vibrations ou la compensation gravitationnelle, tous cruciaux pour des interventions chirurgicales précises.
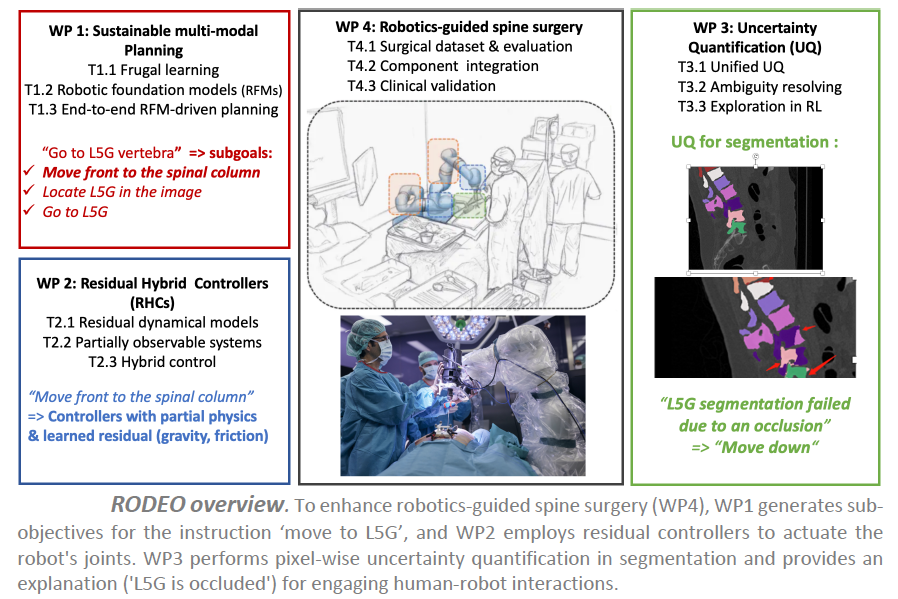
Les objectifs
Le projet RODEO vise à développer la prochaine génération d’IA génératives profondes pour surmonter les principaux défis mentionnés. L’objectif est de concevoir des systèmes d’IA avec une robustesse améliorée en termes de flexibilité et de fiabilité, tout en restant durables, ainsi que des modèles hybrides capables d’intégrer des connaissances physiques du monde.
L’hypothèse centrale de la recherche est que ces améliorations peuvent conduire à une avancée majeure dans la robotique chirurgicale. Des systèmes d’IA plus fiables peuvent améliorer leur acceptation par les experts médicaux et les patients, notamment en leur permettant d’évaluer leur propre confiance ou d’expliquer leurs décisions de manière compréhensible. Les modèles hybrides et durables pourraient considérablement améliorer le niveau d’automatisation dans la co-manipulation robot/chirurgien, réduisant ainsi la charge cognitive des chirurgiens et leur permettant de se concentrer entièrement sur les interventions médicales, ce qui améliorerait les procédures chirurgicales et les soins aux patients.
Les résultats
Dans notre cadre de test pour la chirurgie de la colonne vertébrale, nous attendons des améliorations majeures dans trois domaines principaux :
– concevoir des contrôleurs hybrides capables d’utiliser l’IA pour apprendre les composants résiduels des contrôleurs actuels difficiles à modéliser, tels que les frottements ou les vibrations ;
– augmenter la flexibilité du système avec des IA génératives profondes multimodales pour planifier à long terme en utilisant la perception visuelle et des méthodes basées sur l’IA pour enregistrer les scanners CT préopératoires avec les caméras de profondeur opératoires ;
– doter les systèmes d’IA de la capacité de quantifier leur propre confiance et d’expliquer leurs décisions à l’équipe chirurgicale de manière compréhensible.
Partenariat et collaboration
Le projet ANR RODEO est un projet mono-équipe mené par l’équipe projet MLR (Machine Learning and Robotics) de l’ISI, porté par Nicolas Thome, chercheur à l’ISIR et professeur à Sorbonne Université.
Projet GUIDANCE – « General pUrpose dIalogue-assisted Digital iNformation aCcEss »
Le projet GUIDANCE vise à fédérer la communauté française de recherche en Récupération de l’Information (IR), en réunissant des experts du domaine pour faire progresser le développement de modèles d’Accès à l’Information basés sur le Dialogue (DbIA) exploitant les grands modèles linguistiques (LLM).
Le but du projet est de développer de nouveaux modèles et ressources pour l’accès à l’information interactif, par exemple dialoguer avec un système informatique afin d’accéder à de l’information (éventuellement générée de manière automatique), tout en assurant, d’une part, l’adaptation à des domaines ou langues avec de faibles ressources (par rapport à l’anglais), et d’autre part, l’explicabilité et la véracité des informations générées.
Le contexte
Le projet GUIDANCE s’inscrit dans le contexte des grands modèles linguistiques (LLM) et des systèmes conversationnels (par exemple, ChatGPT, WebGPT), qui ont connu d’importants progrès pratiques au cours des derniers mois. Il vise à mener des recherches sur l’Accès à l’Information Numérique Assisté par Dialogue à Usage Général, en se concentrant particulièrement sur la manière de permettre aux utilisateurs et utilisatrices d’accéder à l’information numérique, dans le but de surmonter plusieurs limitations des LLM actuels :
– Les LLM n’ont pas été conçus avec l’accès à l’information, que ce soit au niveau des tâches de pré-entraînement ou de celles de fine-tuning ;
– Les LLM ont des capacités de généralisation limitées à de nouveaux domaines et/ou langues ;
– La véracité et la fiabilité des résultats sont discutables ;
– Les modèles LLM potentiellement à la pointe de la technologie ne sont pas en accès libre, et la méthodologie scientifique ainsi que l’évaluation adéquate sont à peine décrites dans la littérature scientifique.
Les objectifs
D’un point de vue de la recherche, GUIDANCE aborde quatre défis associés à ce projet :
- Comment concevoir de nouveaux grands modèles linguistiques (LLM) ou réutiliser des LLM pour développer des modèles d’Accès à l’Information basés sur le Dialogue (DbIA) ;
- Comment tirer parti des techniques d’apprentissage machine améliorées par la recherche (ReML) pour améliorer la précision et l’efficacité des systèmes de recherche d’information ;
- Adapter les LLM et développer de nouvelles architectures (pour les modèles DbIA) pour faire face à la faible ressource et à l’adaptation de domaine, en accordant une attention particulière aux langues à ressources faibles ou moyennes (par exemple, l’occitan, le français) ;
- Concevoir des modèles DbIA capables de garantir la véracité et l’explicabilité des informations extraites et synthétisées, tout en préservant la subjectivité de l’utilisateur.
Les résultats
Les résultats attendus du projet GUIDANCE sont multiples, ouvrant la voie à des avancées significatives dans le domaine de l’accès à l’information.
Premièrement, le développement de ressources pour entraîner les modèles d’accès à l’information (mise à disposition de la communauté). Il s’agit de corpus d’apprentissage qui peuvent être utilisés pour entraîner de nouveaux modèles plus puissants.
Deuxièmement, le projet vise à développer de nouveaux modes d’interactions avec les systèmes d’accès à l’information : un moteur de recherche peut être pro-actif pour guider l’utilisateur vers des résultats pertinents (bien plus qu’en proposant les questions proches comme actuellement).
Enfin, la mise à disposition de modèles pré-entraînés pour l’accès à l’information, qui permettront d’utiliser ces modèles interactifs librement, que cela pour la recherche ou bien pour d’autres usages.
Partenariats et collaborations
Porté par Benjamin Piwowarski, chargé de recherche CNRS à l’ISIR (équipe MLIA), le projet GUIDANCE (projet ANR) implique également :
– l’Institut de Recherche en Informatique de Toulouse (IRIT) à travers les deux équipes de recherche IRIS et SIG,
– le Laboratoire d’Informatique de Grenoble (LIG) à travers les équipes de recherche APTIKAL et MRIM,
– et le Laboratoire d’Informatique et Systèmes (LIS) à travers l’équipe de recherche R2I.
Le projet qui a débuté en octobre 2023 rassemble 18 chercheurs et chercheuses de 6 groupes de recherche en Récupération de l’Information (IR) et en traitement du langage naturel (NLP).
Projet Tralalam – Translating with Large Language Models
Le projet TraLaLaM vise à explorer l’utilisation de grands modèles de langue (LLM) pour la traduction automatique, en posant deux questions principales :
– dans quels scénarios les informations contextuelles peuvent-elles être utilisées efficacement par le biais de prompts ?
– pour les scénarios à faibles ressources (en mettant l’accent sur les dialectes et les langues régionales), les LLM peuvent-ils être affinés efficacement sans aucune donnée parallèle ?
Accepté dans le cadre de l’appel ANR 2023 portant sur les très grands modèles de langue (LLM), le projet se positionne au croisement de l’intelligence artificielle, de la linguistique et de la traduction automatique.
Le contexte
Entraînés sur des giga corpus multilingues, les modèles de langue (LLM) peuvent être employés à diverses fins. Une des finalités possibles est la traduction automatique, tâche pour laquelle l’approche à base de LLM permet de répondre simplement à deux points difficiles :
– la prise en charge d’un contexte étendu et enrichi (par des exemples ou des entrées de dictionaires terminologiques) ;
– et la prise en charge de domaines et directions de traduction pour lesquels les données d’apprentissage parallèles sont lacunaires, voire inexistantes.
Les objectifs
L’objectif principal du projet est d’analyser en profondeur la pertinence des LLM.
D’une part, nous nous concentrerons sur des cas d’usage industriels en étudiant des scénarios d’adaptation au domaine, de prise en compte de données terminologiques ou de mémoires de traduction, qui correspondent à des situations réalistes. D’autre part, nous nous intéresserons à la réalisation d’un système de traduction automatique depuis et vers toutes les langues de France à partir d’un LLM massivement monololingue et entrainé avec peu (voire pas du tout) de données parallèles.
Des défis scientifiques significatifs sont à relever, tels que l’extension de modèles pré-entrainés à de nouvelles langues très peu dotées ou encore la prise en charge de textes très idiomatiques, présentant de nombreuses instances d’alternance codique entre une langue minoritaire et le français.
Les résultats
Du point de vue industriel, Tralalam vise à évaluer les coûts et compromis computationnels VS la performance induits par l’utilisation des LLM en traduction automatique. Ces nouvelles architectures ont le potentiel de transformer en profondeur la manière d’entrainer et de déployer opérationnellement des systèmes de traductions. Les outils actuels sont soit toutefois trop gourmands en calcul, soit bien moins performants que les modèles de traduction optimisés pour cette seule tâche.
Concernant les langues de France, en partenariat avec divers acteurs représentant les communautés linguistiques concernées, nous souhaitons aboutir à des solutions opérationnelles pour certaines applications bien ciblées, telles que la traduction de pages Wikipedia, de textes administratifs ou réglementaires, etc.
Partenariats et collaborations
Porté par l’entreprise Systran, le projet Tralalam implique également :
– l’ISIR de Sorbonne Université,
– et l’équipe-projet ALMAnaCH du centre Inria de Paris.
Projet MaTOS – Machine Translation for Open Science
Le projet MaTOS s’intéresse à la traduction automatique (TA) de documents, en étudiant aussi bien aux problèmes de modélisation terminologique que les problèmes de traitement du discours et de son organisation dans un cadre de génération automatique de texte. Il comprend enfin un volet portant sur l’étude des méthodes d’évaluation et une expérimentation à grande échelle sur l’archive HAL.
Le contexte
L’anglais scientifique est la lingua franca utilisée dans de nombreux domaines scientifiques pour publier et communiquer les résultats de la recherche. Pour que ces résultats soient accessibles pour les étudiant·e·s, les journalistes scientifiques ou pour les décideurs·euses, une traduction doit toutefois s’opérer. La barrière de la langue apparaît donc comme un obstacle qui limite ou ralentit la dissémination des connaissances scientifiques. La traduction automatique peut-elle aider à relever ces défis ?
Le projet MaTOS – Machine Translation for Open Science (ou Traduction automatique pour la science ouverte) – est un projet ANR qui a pour objectif de proposer de nouvelles méthodes pour la traduction automatique pour des documents complets, qui posent des problèmes spécifiques aux systèmes de traduction actuels. En appliquant ces méthodes à des textes scientifiques, MaTOS aidera à fluidifier la circulation et la diffusion des connaissances scientifiques par une traduction automatique améliorée.
Les objectifs
Le projet MaTOS (Machine Translation for Open Science) vise à développer de nouvelles méthodes pour la traduction automatique intégrale de documents scientifiques, ainsi que des métriques automatiques pour évaluer la qualité des traductions produites. Notre principale cible applicative est la traduction d’articles scientifiques entre le français et l’anglais, pour laquelle des ressources linguistiques peuvent être exploitées pour obtenir des traductions plus fiables, aussi bien dans une optique d’aide à la publication que pour des besoins de lecture ou de fouille de textes. Les efforts pour améliorer la traduction automatique de documents complets sont toutefois freinés par l’incapacité des métriques automatiques existantes à détecter les faiblesses des systèmes comme à identifier les meilleures façons d’y remédier. Le projet MaTOS se propose d’aborder ces deux difficultés de front.
Les résultats
Ce projet s’inscrit dans un mouvement visant à automatiser le traitement d’articles scientifiques. Le domaine de la traduction automatique n’échappe pas à cette tendance, en particulier pour ce qui concerne le domaine bio-médical. Les applications sont nombreuses : fouille de textes, analyse bibliométrique, détection automatique de plagiats et d’articles rapportant des conclusions falsifiées, etc. MaTOS ambitionne de tirer profit des résultats de ces travaux, mais également d’y contribuer de multiples manières :
– en développant de nouvelles ressources ouvertes pour la traduction automatique spécialisée ;
– en améliorant, par l’étude des variations terminologiques, la description des marqueurs de cohérence textuelle pour les articles scientifiques ;
– en étudiant de nouvelles méthodes de traitement multilingue pour ces documents ;
– en proposant des métriques dédiées à la mesure des progrès pour ce type de tâches.
Le résultat final permettra, par une traduction améliorée, de fluidifier la circulation et la diffusion des savoirs et des connaissances scientifiques.
Partenariats et collaborations
Coordonné par François Yvon, chercheur à l’ISIR (équipe MLIA) de Sorbonne Université, le projet MaTOS réunit trois autres partenaires :
– l’Inist (Institut de l’Information Scientifique et Technique),
– et l’Inria.
Projet « Le langage et sa sémantique »
Le contexte
Ce groupe de travail s’intéresse aux différentes formes de langage (texte écrit et langage oral, parole et signaux sociaux, geste, visage, etc.) ainsi qu’à la notion de sémantique qui en découle. A l’intersection entre le traitement automatique du langage, la perception, les sciences cognitives et la robotique, le langage soulève de nombreux enjeux dérivant de l’analyse à la génération, que ce soit dans un contexte individuel ou interactif.
Voici une liste non exhaustive d’exemples d’applications tirées de nos domaines de recherche :
– Prise en compte des hésitations, du rire et autres signaux sociaux
– Lien parole et comportements non verbaux ;
– Dialogues contextualisés (historique, tâche, interaction) / Systèmes de questions-réponses ;
– Synthèse textuelle d’information et d’interaction ;
– Recommandation et recherche d’information ;
– Analyse et représentation de la sémantique ;
– Variation de style ou de contenu.
Les objectifs
L’objectif de ce groupe est de rassembler des chercheuses et chercheurs ayant des expertises différentes autour du langage. A ce jour, les activités mises en place sont essentiellement des groupes de discussion ou présentation scientifiques dans l’objectif de faire émerger des centres d’intérêts communs.
Sur le long terme, un des enjeux sera de mettre en place des co-supervisions de stagiaires et/ou doctorantes et doctorants autour de cette thématique ou des mini-projets scientifiques.
Partenariats et collaboration
Le projet « Le langage et sa sémantique » est un projet fédérateur, interne à l’ISIR, qui n’implique pas de collaboration extérieure au laboratoire.
Contact du projet : projet-federateur-langage(at)listes.isir.upmc.fr
Projet COST – Modélisation des tâches de recherche complexes
Les moteurs de recherche, et plus généralement les systèmes de recherche, constituent le principal accès à au Web – une bibliothèque numérique mondiale, en permettant aux personnes d’effectuer des tâches de recherche. Dans le projet CoST, nous envisageons de passer de moteurs de recherche à des moteurs d’accomplissement de tâches, en aidant de manière dynamique les utilisateurs à prendre les meilleures décisions, leur permettant ainsi d’accomplir des tâches de recherche multi-étapes et complexes. Cela nécessite le développement (1) de modèles plus prévisibles et automatiques de l’interaction utilisateur-système et des tâches de recherche et (2) de modèles d’accès à l’information plus orientés vers les tâches.
Le contexte
Au cours des dernières années, le niveau de complexité des tâches de recherche a considérablement augmenté, passant de tâches simples comme la recherche de faits à des tâches plus intensives axées sur les connaissances, comme la recherche par hypothèse pour le diagnostic médical ou l’apprentissage humain à des fins éducatives. Ces tâches s’étalent sur plusieurs sessions, nécessitent une interaction soutenue entre l’utilisateur et le système, et sont structurées en plusieurs sous-tâches et/ou plusieurs sujets. Si les systèmes de recherche actuels sont très efficaces pour les tâches simples de consultation d’information (recherche de faits), ils sont incapables de guider les utilisateurs engagés dans des processus de recherche complexes. Ainsi, paradoxalement, alors que nous considérons aujourd’hui que la recherche d’informations est « naturelle » et « facile », les systèmes de recherche ne sont pas encore en mesure de fournir un support adéquat pour réaliser un large éventail de tâches de recherche dans la vie réelle.
Les objectifs
– Modéliser des modèles de comportement de recherche à partir des interactions des utilisateurs. L’objectif est d’extraire des modèles de comportement de haut niveau des utilisateurs en reliant conjointement les multiples interactions observables des utilisateurs (par exemple, la reformulation des requêtes, les clics) aux sous-tâches et aux attributs des tâches (par exemple, le niveau de complexité cognitive) et au contexte cognitif de l’utilisateur (par exemple, la connaissance du domaine).
– Apprendre des représentations de tâches de recherche complexes. Par analogie avec l’importance de la représentation des requêtes et des documents dans les modèles traditionnels de RI, cette étape est fondamentale pour la conception de modèles d’accès à l’information basés sur les tâches. Dans CoST, nous essayons de construire les représentations des tâches qui soutiennent leur achèvement sur la base d’une assistance pilotée par le système.
– Conception de modèles d’accès à l’information axés sur les tâches. Nous considérons ici le problème de l’adéquation entre la pertinence de l’information et la réalisation de la tâche. Seuls quelques travaux récents ont abordé ce défi dans le contexte de tâches spécifiques. Notre objectif dans le projet CoST est de fournir des solutions aux tâches de recherche complexes génériques en s’appuyant sur les représentations apprises et la compréhension des capacités de recherche des utilisateurs cognitifs.
Les résultats
Les résultats attendus pour le projet consiste en :
– Un ensemble de données avec des journaux d’utilisateurs (générés lors de tâches de recherche complexes, en français).
– Des publications dans les principales conférences et revues sur la RI.
Partenariats et collaborations
Le consortium du projet est composé de :
– L’ISIR. Objectif : Modèles pour les utilisateurs engagés dans des tâches de recherche complexes.
– Le laboratoire Cognition, Langues, Langage, Ergonomie de Toulouse 2 (CLLE). Objectif : Identifier les processus et stratégies cognitifs développés par les utilisateurs finaux au cours de tâches d’apprentissage humain cognitif afin d’améliorer les modèles cognitifs de recherche d’information utilisés au cours de la première étape de la récupération.
– Le laboratoire d’Informatique de Grenoble (LIG). Objectif : Modéliser la recherche par extraction basée sur les tâches.
– L’Institut de Recherche en Informatique de Toulouse (IRIT). Objectif : Modéliser les représentations des tâches et sous-tâches de recherche et Identifier des modèles connexes de comportements d’utilisateurs dans les sessions de recherche.
Projet ANR https://www.irit.fr/COST/
Projet ADONIS : Asynchronous Decentralized Optimization of machiNe learnIng modelS
Les modèles modernes d’apprentissage en profondeur, tout en fournissant des résultats de pointe sur divers benchmarks, deviennent prohibitifs en termes de calcul. Le parallélisme est l’une des principales caractéristiques qui permet aux modèles à grande échelle d’être entraînés de bout en bout dans un délai raisonnable. En pratique, ce parallélisme revient à répliquer le modèle sur plusieurs GPU (Graphics Processing Unit) coordonnés par un CPU (Central Processing Unit). Cela garantit que toutes les opérations sont homogènes et synchrones, ce qui est nécessaire lors de la formation avec rétropropagation. Le projet ADONIS explore les moyens théoriques et pratiques de former des modèles statistiques de manière décentralisée et asynchrone. L’objectif ultime est de tirer parti de la puissance de calcul potentiellement énorme cachée dans l’Internet des objets et de la mettre à la disposition des praticiens de l’apprentissage automatique.
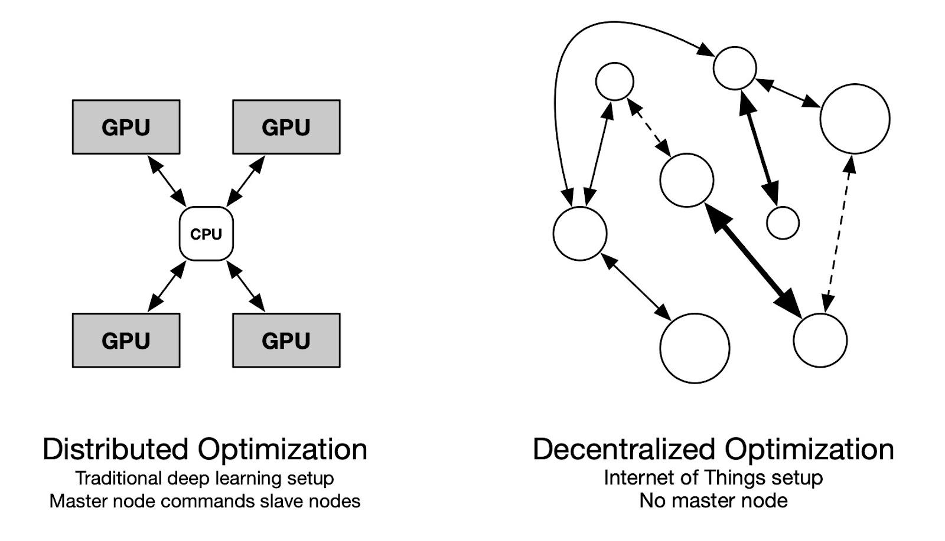
Le contexte
Les modèles d’apprentissage automatique modernes, généralement des modèles de langage à la pointe de la technologie, nécessitent d’utiliser des ressources informatiques considérables. Le parallélisme des données s’est concentré sur la distribution des calculs de manière centralisée, avec une gamme de GPU gérés par un CPU central. Toute cette coordination est nécessaire pour former des modèles à grande échelle, car l’algorithme de rétropropagation largement utilisé nécessite des calculs en série à travers les couches. Alors qu’un nombre croissant d’appareils informatiques devient disponible sur Internet, peu de littérature traite de la formation dans un environnement hétérogène et peu fiable. Le projet ADONIS explore les problèmes posés lors de la formation d’un modèle statistique sur un cluster de dispositifs hétérogènes avec une connectivité variable. Les membres du projet de l’ISIR ont obtenu des résultats encourageants vers l’optimisation asynchrone décentralisée. Ce projet est motivé par le fait que si la littérature couvre les algorithmes synchrones, la décentralisation et l’asynchronisme restent difficiles à étudier, en particulier dans le cas de l’apprentissage en profondeur. L’apport de l’ISIR en optimisation convexe distribuée est l’occasion d’étudier le problème d’un point de vue théorique, tandis que son expérience en apprentissage décentralisé sera utile pour souligner la pertinence pratique des apports.
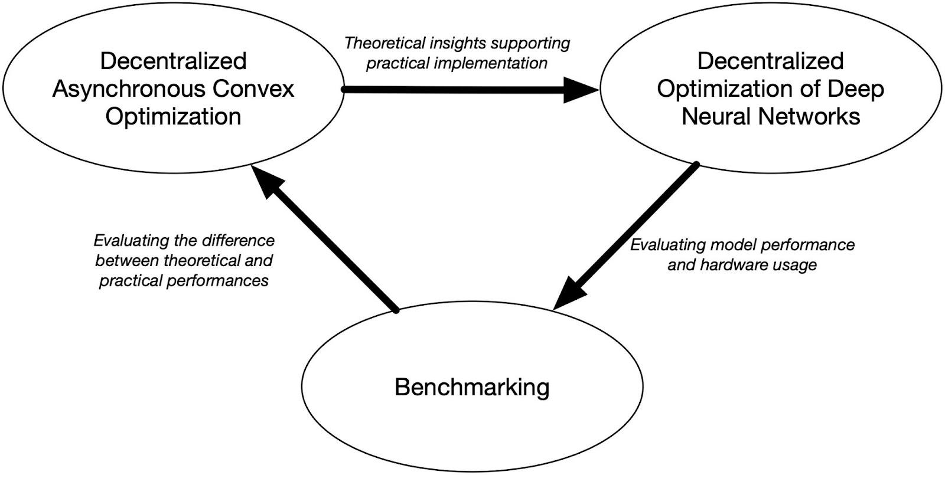
Les objectifs
– Le premier objectif du projet est de dériver un cadre théorique pour rendre compte de la dynamique de formation qui doit être modélisée pour le cas d’utilisation en question. À savoir, la formation d’un modèle statistique sur un cluster d’appareils hétérogènes avec une connectivité potentiellement mauvaise et une topologie variable devrait bénéficier de l’étude de l’optimisation décentralisée asynchrone.
– De plus, pour évaluer dans quelle mesure les résultats théoriques atteignent leur objectif dans des cas d’utilisation réels, l’objectif du projet est de dériver des algorithmes compétitifs par rapport à leurs homologues traditionnels.
– Enfin, le projet propose de dériver une procédure objective facilement implémentable pour évaluer les performances de sorte que tout chercheur puisse reproduire tout résultat asynchrone dans un environnement contrôlé et le comparer à ses propres contributions.
Les résultats
Le projet ADONIS est motivé par une littérature en émergence lente mais plutôt dispersée en optimisation décentralisée asynchrone. Le PI a initié une ligne de travail sur l’apprentissage glouton qui permet de briser le verrou imposé par l’algorithme traditionnel de rétropropagation. Bien que ce travail montre des résultats prometteurs sur des jeux de données du monde réel, une première ligne de résultats théoriques est attendue de l’étude de l’optimisation convexe asynchrone décentralisée. À savoir, les taux de convergence optimaux et les conditions sur la matrice de connectivité variant dans le temps devraient être dérivés prochainement. Compte tenu de certaines connaissances théoriques sur la dynamique de formation décentralisée, l’un des objectifs est d’adapter les performances de l’apprentissage glouton découplé à des ensembles de données tels que Imagenet. Une meilleure compréhension de l’impact des astuces d’ingénierie nécessaires pour faire face à la contrainte de ressources est attendue, plus précisément sur les stratégies de quantification et l’utilisation d’un tampon de relecture. Enfin, un ensemble de procédures objectives pour évaluer les performances du modèle devrait émerger de l’expérimentation extensive prévue au cours du projet.
Partenariats et collaborations
Le projet coordonné par l’équipe MLIA est structuré autour de plusieurs organismes :
– le MILA – Institut québécois d’intelligence artificielle de Montréal,
– le centre INRIA de l’Université de Lille,
– et de l’Ecole Polytechnique de l’Université Paris-Saclay.
Projet SESAMS : SEarch-oriented ConverSAtional systeMS
Jusqu’à présent, dans le cadre de la recherche traditionnelle sur la recherche d’information (RI), le besoin d’information de l’utilisateur est représenté par un ensemble de mots-clés et les documents renvoyés sont principalement déterminés par leur inclusion dans ces mots-clés.
Le projet SESAMS envisage un nouveau paradigme dans la RI dans lequel l’utilisateur peut interagir avec le moteur de recherche en langage naturel par l’intermédiaire d’un système conversationnel. Nous appelons cela des systèmes conversationnels orientés recherche. Plusieurs défis importants sont sous-jacents ce nouveau paradigme, que nous aborderons dans ce projet :
– comprendre le besoin d’information de l’utilisateur en exploitant à la fois les interactions en langage naturel et le feedback implicite des utilisateurs ;
– concevoir un système proactif qui anticipe les actions des utilisateurs et leur intention de recherche en sollicitant directement l’utilisateur ;
– et évaluer ce nouveau paradigme en concevant de nouveaux cadres d’évaluation théoriques et pratiques pour les systèmes conversationnels orientés recherche et en construisant des ensembles de données à grande échelle adaptés qui permettraient d’apprendre et d’évaluer les modèles proposés.
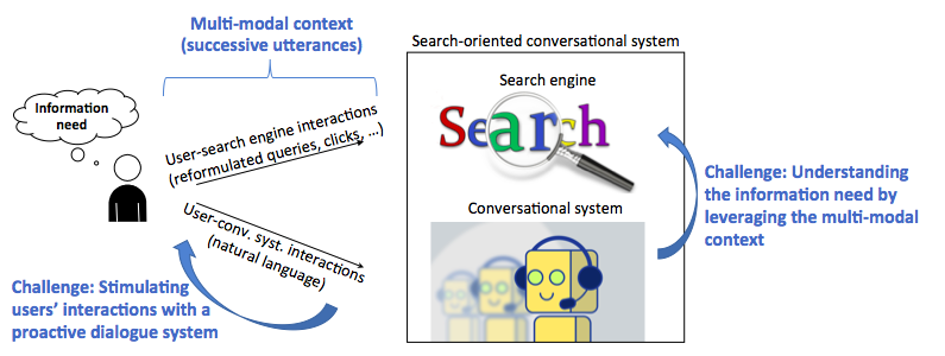
Le contexte
La RI conversationnelle a une forte relation avec les systèmes de dialogue (chat-bots). Dans les deux cas, une conversation à plusieurs tours est établie entre l’utilisateur et le système. Cependant, l’objectif de la RI conversationnelle diffère de celui d’un système de bavardage général : l’objectif est de trouver plus facilement les informations pertinentes souhaitées d’une manière plus naturelle, plutôt que de simplement maintenir la conversation. Elle est également différente d’une conversation orientée vers une tâche dans un monde fermé, car aucun modèle basé sur un domaine en particulier domaine ne peut être construit pour la RI dans un domaine ouvert.
La RI conversationnelle est également liée aux questions-réponses (QA). En effet, la RI est généralement utilisée comme première étape des systèmes de QA pour localiser un petit ensemble de documents ou de passages candidats dans lesquels des réponses peuvent être trouvées. Les moteurs de recherche actuels incluent également les systèmes de QA en tant que sous-module, car des questions de plus en plus complètes sont soumises aux moteurs de recherche. Cependant, une grande différence entre la RI conversationnelle et la QA est qu’un besoin d’information ne peut généralement pas être décrit par une question précise. La réponse à une telle requête n’est pas non plus un type d’entité spécifique, mais toute information pertinente. Par conséquent, la RI conversationnelle doit répondre à des demandes d’utilisateurs plus larges que la QA.
Les objectifs
Nous présentons deux innovations majeures dans ce projet :
– Un nouveau paradigme de RI qui transforme le cadre bien établi de la RI ad-hoc en un cadre naturaliste. Cela implique la conception de modèles de RI capables de 1) capturer le besoin d’information des utilisateurs dans un contexte hétérogène (caractérisé par des interactions en langage naturel et le feedback implicite des utilisateurs) et 2) de rendre la session de recherche proactive dans laquelle le système anticipe ou affine activement le besoin des utilisateurs.
– De nouveaux modèles d’apprentissage automatique exploitant les interactions des utilisateurs de RI qui imposent 1) la prise en compte des particularités des actions de RI (par exemple, la reformulation des requêtes, l’expression des préférences en matière de documents, etc.) et 2) l’optimisation de l’efficacité globale de la recherche.
En outre, nous relevons les défis suivants :
– Exploitation d’un contexte hétérogène. Les différents niveaux d’interactions (utilisateur-système conversationnel et utilisateur-moteur de recherche) fournissent un contexte de session riche qu’il est crucial d’exploiter. Cependant, ces interactions sont hétérogènes puisqu’elles comprennent à la fois des interactions exprimées en langage naturel et des retours implicites collectés à travers les logs de recherche utilisateurs. Une question clé du projet est d’exploiter ce contexte hétérogène et de définir comment ces deux types d’information pourraient être pris en compte à la fois pour comprendre le besoin d’information des utilisateurs et pour engager le système dans des interactions proactives.
– Apprendre avec une petite quantité de données. Le choix méthodologique de concevoir des modèles formels basés sur l’apprentissage profond donne lieu au défi critique de la quantité de données pour l’apprentissage de modèles neuronaux profonds. C’est particulièrement le cas dans ce projet puisque le cadre adressé basé sur des systèmes conversationnels orientés recherche est un nouveau paradigme qui a émergé très récemment. Par conséquent, à notre connaissance, il n’existe pas de jeux de données impliquant simultanément les interactions des utilisateurs avec les moteurs de recherche et les systèmes conversationnels. Un autre enjeu du projet est d’intégrer des techniques basées sur l’augmentation des données ou la simulation d’utilisateurs pour apprendre les modèles que nous proposons.
– Concevoir des cadres d’évaluation adaptés. Il s’agit d’un défi majeur dans le projet puisque nous abordons un nouveau paradigme de RI qui implique un cadre plus complexe et impose la conception de nouveaux ensembles de données, protocoles, métriques et lignes de base. En tenant compte du fait que la construction d’ensembles de données à grande échelle basés sur les logs de recherche des utilisateurs réels pourrait être longue et coûteuse, ce défi impose également de simuler les journaux des utilisateurs, ce qui n’est pas évident dans un cadre aussi complexe avec des interactions hétérogènes.
Les résultats
La contribution attendue de ce projet est double, à la fois dans les domaines de l’apprentissage profond et de la RI :
– l’introduction et la mise en œuvre d’un nouveau paradigme en RI reposant sur des systèmes conversationnels orientés recherche ;
– l’introduction de l’humain dans le cadre de l’apprentissage automatique, en prenant en considération les interactions des utilisateurs avec le moteur de recherche et le système conversationnel.
Les participants attacheront une importance particulière à la publication de la contribution proposée dans des conférences et des revues de haut niveau dans les communautés de la recherche d’information (par exemple, SIGIR, CIKM, ECIR) et de l’apprentissage automatique (par exemple, NIPS, ICML, ICLR). Nous participerons également à des ateliers traitant de ce paradigme émergent (CAIR à SIGIR ou SCAI à ICTIR). Tous les codes sources des algorithmes proposés seront mis à la disposition de la communauté en open source.
Partenariats et collaborations
SESAMS est un projet développé à l’ISIR sous la direction de Laure Soulier (Maîtresse de Conférences) qui est spécialisée dans la recherche d’information (en particulier, la RI interactive) et l’apprentissage par représentation. Le projet est mené en collaboration avec des spécialistes aux compétences complémentaires :
– Ludovic Denoyer de Sorbonne Université (apprentissage par renforcement et réseaux de neurones profonds),
– Vincent Guigue de l’ISIR (apprentissage par représentation et traitement du langage naturel),
– Philippe Preux du CRIStAL/Inria Lille (apprentissage par renforcement et réseaux de neurones profonds),
– et Jian-Yun Nie du DIRO/Université de Montréal (recherche d’information et apprentissage profond).
Projet ACDC – Apprentissage Contrefactuel pour Data-to-text Contrôlé
Le projet ACDC s’appuie sur les avancées en génération de la langue via des architectures neuronales, pour aborder des problématiques de synthèse textuelle d’informations contenues sous forme de données tabulaires. Un accent particulier est porté sur la recherche d’invariance dans les données d’entrée, l’extraction d’opérateurs de compression haut-niveau et la personnalisation des sorties produites. On propose de s’appuyer sur des techniques d’apprentissage profond et par renforcement, impliquant l’inférence, la manipulation et le décodage de représentations d’opérations de synthèse de contenu dans un espace sémantique continu. L’objectif est de produire des espaces de représentation réguliers, encodant divers types de symétrie sémantique des opérateurs appliqués aux contenus, permettant de contrôler le mode de compression des textes générés, en fonction d’un tableau d’entrée. L’inférence d’opérateurs explicites envisagée dans ce projet permettra de mettre en place des modèles interprétables, facilitant ainsi l’analyse des synthèses produites, et la planification de rapports textuels cohérents, détaillant divers aspects saillants des données d’entrée.
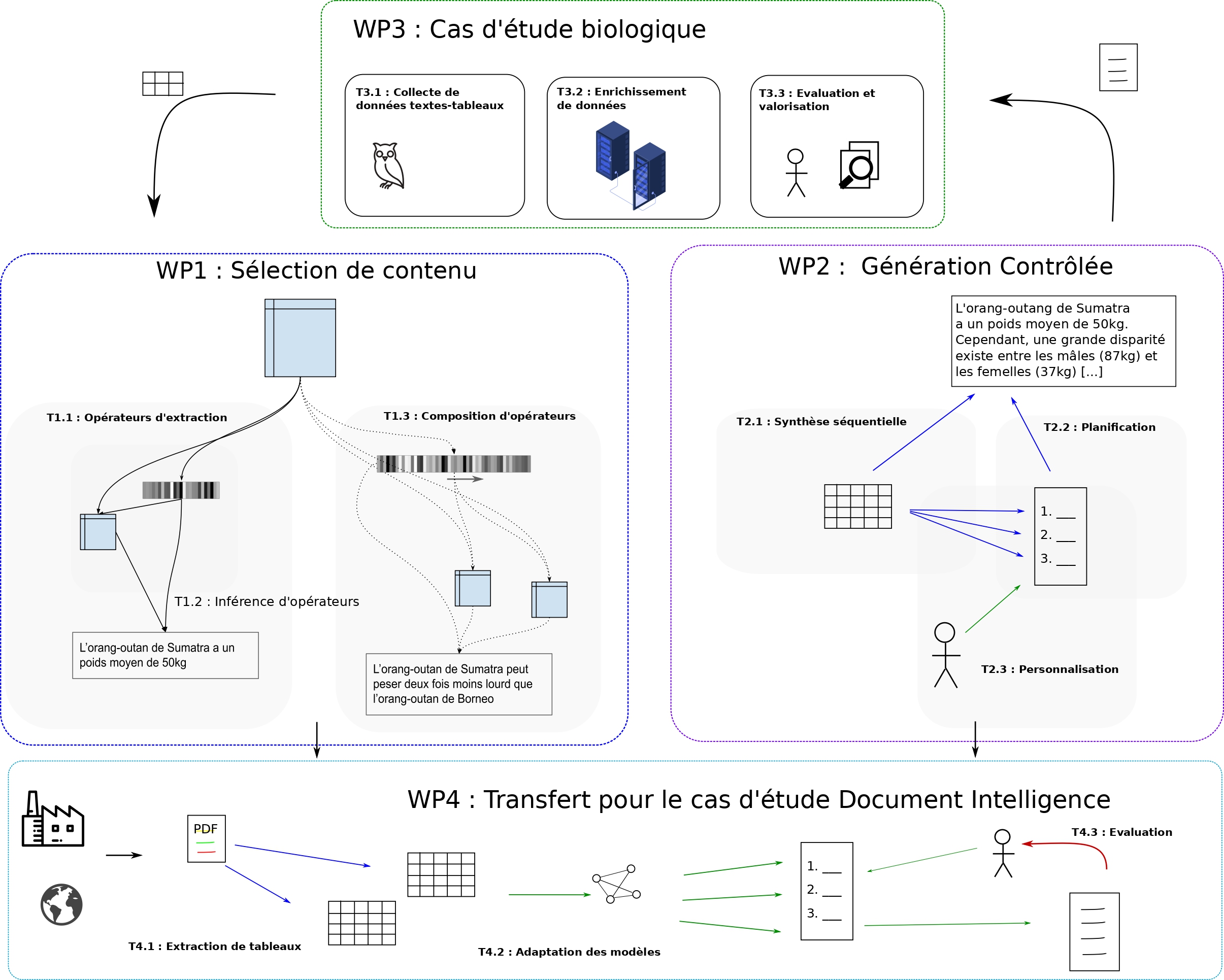
Le contexte
La très grande disponibilité des données est un fait bien établi dans notre société. Que les données proviennent de textes, de traces d’utilisateurs, de capteurs ou encore de bases de connaissances, l’un des défis communs est de comprendre et d’accéder rapidement aux informations contenues dans ces données. Une des réponses à ce défi consiste à générer des synthèses textuelles des données considérées, le langage naturel présentant de nombreux avantages en terme d’interprétabilité, de compositionnalité, d’accessibilité et de transférabilité. Néanmoins, si la génération de résumés pour données textuelles est un problème pour lequel les solutions commencent à être satisfaisantes, la génération de descriptions textuelles dans un cadre plus général (par exemple, conditionnelles à des données numériques ou structurées) constitue toujours un problème particulièrement difficile. Ce problème fait référence à un champ émergent dans le domaine du traitement du langage naturel, appelé Data-to-Text, possédant de très nombreuses applications, notamment dans les domaines scientifiques, du journalisme, de la santé, du marketing, de la finance, etc.
L’ensemble des approches récentes de data-to-text travaillent de manière supervisée, sans représentation explicite des opérateurs d’extraction qu’ils manipulent pour passer du contenu tabulaire global à la synthèse textuelle. Ce projet se démarque car il propose de s’intéresser à l’expression de ces opérateurs, afin de gagner en interprétabilité des modèles, ainsi qu’en capacité de contrôle sur les textes générés. En outre, si dans un cadre figé bien défini, avec de nombreuses ressources pour la supervision, il est possible de s’affranchir de l’expression explicite de ces opérateurs, car le mode de sélection peut être implicitement adapté en fonction des sorties désirées, ce n’est plus envisageable dans un cadre plus large avec une grande hétérogénéité des données d’entrée et des attendus dans un contexte où la supervision est limitée.
Les objectifs
Notre démarche, en forte rupture avec les approches de la littérature, est donc de chercher à inférer les opérateurs d’extraction de contenu permettant de passer d’un tableau à un texte observé, en ayant pour but d’avoir un apprentissage robuste, qui soit à la fois fortement généralisable et contrôlable par un utilisateur.
Les défis que ce projet cible sont donc :
– l’inférence d’opérateurs d’extraction d’information dans les tableaux,
– la gestion de l’hétérogénéité dans les données d’entrée,
– et la synthèse contrôlée de descriptions textuelles.
Le projet sera centré sur deux cas d’étude complémentaires, aux propriétés différentes, dans les domaines de l’analyse de données biologiques et l’analyse de documents d’entreprise. Il est articulé autour de 4 lots de travail :
- le WP1 s’intéresse à l’apprentissage d’opérateurs et l’extraction de contenu,
- le WP2 se focalise sur la planification et la personnalisation des synthèses produites,
- le WP3 concerne la production de données supervisées et l’évaluation des synthèses produites par la communauté biologique,
- le WP4 concerne des problématiques de transfert au cas d’étude financier, où les capacités de supervision sont limitées, mais les enjeux économiques considérables.
Les résultats
Si l’on n’ambitionne pas dans ce projet d’atteindre un niveau humain pour interpréter des tableaux de données, nous sommes convaincus que les méthodes que l’on envisage auront un fort impact pour la communauté scientifique, car ils définissent des mécanismes d’adaptation haut-niveau pour la compréhension des données, dans les cadres applicatifs visés. Les avancées récentes en apprentissage profond (par exemple, transformeurs structurels), nous permettent d’envisager sereinement ce genre d’objectifs, qui constitueront un pas important pour la communauté vers des systèmes généralisables et personnalisables, dont l’apprentissage ne se contente pas d’imiter les sorties observées mais recherche à combiner des stratégies d’extraction complexes pour répondre à des besoins peu définis. Pour la communauté TAL, ce genre d’avancée est cruciale pour définir divers types de systèmes guidés par les données à disposition, plutôt que d’apprendre à simplement imiter des humains. Le séquençage et la planification d’opérateurs est une proposition à fort potentiel pour dépasser les problématiques d’effondrement de postérieure ou de biais d’exposition auxquels sont très souvent confrontés les systèmes de génération de la langue naturelle. Enfin, le domaine de l’apprentissage statistique est confronté à un besoin grandissant de méthodes capables d’expliquer les décisions qu’elles prennent (xAI), portées par diverses politiques pour la protection des individus face aux machines. Un reproche très souvent fait aux architectures neuronales concerne leur opacité, ce projet apporte un élément de réponse important à cette critique, par la définition de modèles d’extraction et de verbalisation basés sur des opérateurs explicites, dont on peut interpréter la sémantique, tout en conservant de grandes capacités d’expressivité.
Pour le domaine biologique, au-delà d’une simple amélioration, par synthèse textuelle, des conditions d’accès aux informations contenues dans les tableaux de données scientifiques, le projet ACDC pourra apporter une aide à la décision importante, en pointant des informations remarquables pouvant suggérer des orientations pour des recherches à mener. Pour le domaine du Document Intelligence, la thématique du data-to-text présente des enjeux considérables pour le traitement d’informations critiques dans les secteurs de la finance, de la gestion des risques et du suivi des réglementations. L’analyse et l’interprétation des données produites par les entreprises est un enjeu crucial pour la réglementation, le suivi, l’analyse et l’amélioration du fonctionnement de structures géantes et mondialisées dont l’influence est aujourd’hui considérable. Les impacts à court terme du projet correspondent à l’intégration de méthodes efficaces pour extraire les éléments importants des tableaux de manière facilement interprétable par des auditeurs financiers, comme ceux des clients de RECITAL, qui sont confrontés à l’analyse de longs rapport pour prendre des décisions de subvention importantes en fonction des politiques courantes. À plus long terme, on peut envisager que ce genre de projet aboutira à des systèmes capables d’interpréter seuls des rapports entiers et émettre un avis circonstancié, avec prise en compte de la multi-modalité des documents analysés. Ce projet est un pas important dans ce sens et ouvre de nombreuses possibilités pour le futur.
Partenariats et collaborations
Le consortium réunit trois partenaires avec de fortes compétences en apprentissage profond et par renforcement pour la modélisation de données non structurées, le data-to-text, la recherche d’information et la génération du langage naturel.
– L’équipe MLIA de Sorbonne Université, intégrée depuis peu au laboratoire ISIR, est spécialisée en apprentissage statistique et apprentissage profond. C’est l’une des entités leader en apprentissage profond en France. Sa recherche va de la conception théorique aux développements algorithmiques, pour de nombreux domaines d’application tels que la vision par ordinateur, le traitement du langage naturel et l’analyse de données complexes. L’apprentissage de représentation, l’inférence bayésienne et l’apprentissage par renforcement pour la génération de données structurées sont au cœur de ses recherches depuis de nombreuses années.
– Le LAMSADE, de l’Université Paris Dauphine, est un laboratoire d’Informatique initialement dédié à l’aide à la décision et la recherche opérationnelle, et dont une partie des membres s’est spécialisée dans l’apprentissage profond, notamment pour le traitement et la génération de la langue.
– Le troisième partenaire du projet reciTAL est une PME dont l’activité R&D est centrée sur le traitement automatique du langage. Son implication permet de confronter les avancées du projet à des cas d’usages industriels avec enjeux très importants dans le domaine du Document Intelligence.
– Le Muséum National d’Histoire Naturelle (MNHN – Sorbonne Université) vient compléter le consortium, en y apportant sa grande expertise scientifique dans le domaine de la biologie, pour la spécification des attendus, la constitution des ressources et la validation des sorties générées.
La robotique représente un défi pour les méthodes d’apprentissage car elle combine les difficultés suivantes : espaces d’état et d’action de grande dimension et continus, récompenses rares, monde dynamique, ouvert et partiellement observable avec des perceptions et des actions bruitées. Leur mise en œuvre est donc délicate et nécessite une analyse poussée des tâches à accomplir, ce qui réduit leur potentiel d’application. Dans le projet Européen DREAM, nous avons défini les bases d’une approche développementale permettant de combiner différentes méthodes pour réduire ces contraintes et donc augmenter les capacités d’adaptation des robots par le biais de l’apprentissage.
Le contexte
La conception de robots nécessite d’anticiper toutes les conditions auxquelles ils peuvent être confrontés et de prévoir les comportements appropriés. Une situation imprévue peut donc provoquer un dysfonctionnement susceptible de se reproduire si les mêmes conditions surviennent de nouveau. Ce manque d’adaptation est un frein à de nombreuses applications de la robotique, en particulier lorsqu’elles ciblent un environnement non contrôlé comme notre environnement quotidien (pour des robots compagnons, par exemple) ou plus généralement pour des robots collaboratifs, c’est-à-dire agissant au contact d’humains. Les méthodes d’apprentissage artificiel pourraient aider à rendre les robots plus adaptatifs, si toutefois elles parviennent à surmonter les multiples difficultés liées au contexte de la robotique. Ce sont ces difficultés spécifiques que ce projet se propose d’aborder.
Les objectifs
L’objectif du projet est d’aider à concevoir des robots en interaction avec un environnement non contrôlé, sur des tâches pour lesquelles le comportement désiré est partiellement connu ou même totalement inconnu.
Dans ce contexte, l’apprentissage permet de laisser le robot explorer son environnement en autonomie, afin d’en extraire des représentations sensorielles, sensori-motrices ou purement motrices pertinentes. Par exemple, apprendre à reconnaître des objets, identifier sont ceux qui sont manipulables, apprendre à les saisir, les pousser, les jeter, etc. Explorer le vaste espace sensori-moteur de manière pertinente est central, d’autant plus que nombre d’interactions sont rares (la probabilité d’attraper un objet avec un mouvement purement aléatoire est quasiment nulle).
Nous nous intéressons donc à la construction de ces représentations et nous appuyons sur une approche modulaire et itérative visant à explorer les capacités du robot et à en déduire des représentations qui faciliteront la résolution des tâches qui se présentent, que ce soit avec des méthodes de planification ou d’apprentissage.
Les résultats
La création de représentations d’états et d’actions susceptibles de servir ultérieurement nécessite dans un premier temps de générer des comportements pertinents par rapport aux capacités du robot. Un comportement est pertinent s’il met en avant la capacité du robot à obtenir un effet particulier en interagissant avec son environnement. Sachant que beaucoup de mouvements du robot ne créent aucun effet, découvrir les effets que le robot est susceptible de générer est difficile. A cela s’ajoute la difficulté d’explorer pour apprendre des comportements sans disposer de représentations appropriées.
Nous nous appuyons donc sur des algorithmes d’exploration basés notamment sur de la recherche de nouveauté et des algorithmes de Qualité-Diversité pour générer des comportements d’exploration en grande quantité et en déduire des espace d’état et d’action appropriés pour des apprentissages ultérieurs.

Partenariats et collaborations
Le projet Européen DREAM, coordonné par Sorbonne Université (FET H2020 2015-2018), a lancé cette thématique de recherche au laboratoire (http://dream.isir.upmc.fr/).
Son consortium était composé de :
– l’ENSTA-ParisTech, en France,
– Sorbonne Université, en France,
– l’Université de la Corogne, en Espagne,
– l’Université d’Édimbourg au Royaume-Uni,
– la Vrije Universiteit Amsterdam au Pays-Bas.
Il s’agissait d’un projet académique, sans partenaire industriel.
Elle se poursuit dans le cadre de plusieurs projets visant à appliquer ces travaux à un contexte industriel. La capacité d’adaptation de l’apprentissage est destinée à aider les ingénieurs dans la phase de conception et de mise à jour du comportement d’un robot. Le projet Européen SoftManBot (http://softmanbot.eu) vise des applications à la manipulation d’objets déformables. Il dispose d’un consortium de 11 partenaires, notamment SIGMA, à Clermont-Ferrand, l’IIT à Gênes et des entreprises comme Decathlon et Michelin. Le projet VeriDREAM (https://veridream.eu/), en collaboration avec le DLR, l’ENSTA-Paristech, Magazino GmbH, Synesis et GoodAI, vise à faciliter le transfert de ces méthodes dans un contexte industriel plus large, incluant en particulier des petites et moyennes entreprises avec un focus sur les secteurs de la logistique et du jeu vidéo.
