
Projet ACDC – Apprentissage Contrefactuel pour Data-to-text Contrôlé
La très grande disponibilité des données est un fait bien établi dans notre société. Que les données proviennent de textes, de traces d’utilisateurs, de capteurs, de robots, ou encore de bases de connaissances, l’un des défis communs est d’accéder rapidement aux informations contenues dans ces données. Une des réponses à ce défi consiste à générer des synthèses textuelles des données considérées, le langage naturel présentant de nombreux avantages en terme d’interprétabilité, de compositionnalité, d’accessibilité et de transférabilité. La génération de descriptions textuelles constitue un problème qui fait référence à un champ émergent dans le domaine du traitement du langage naturel, appelé Data-to-Text.
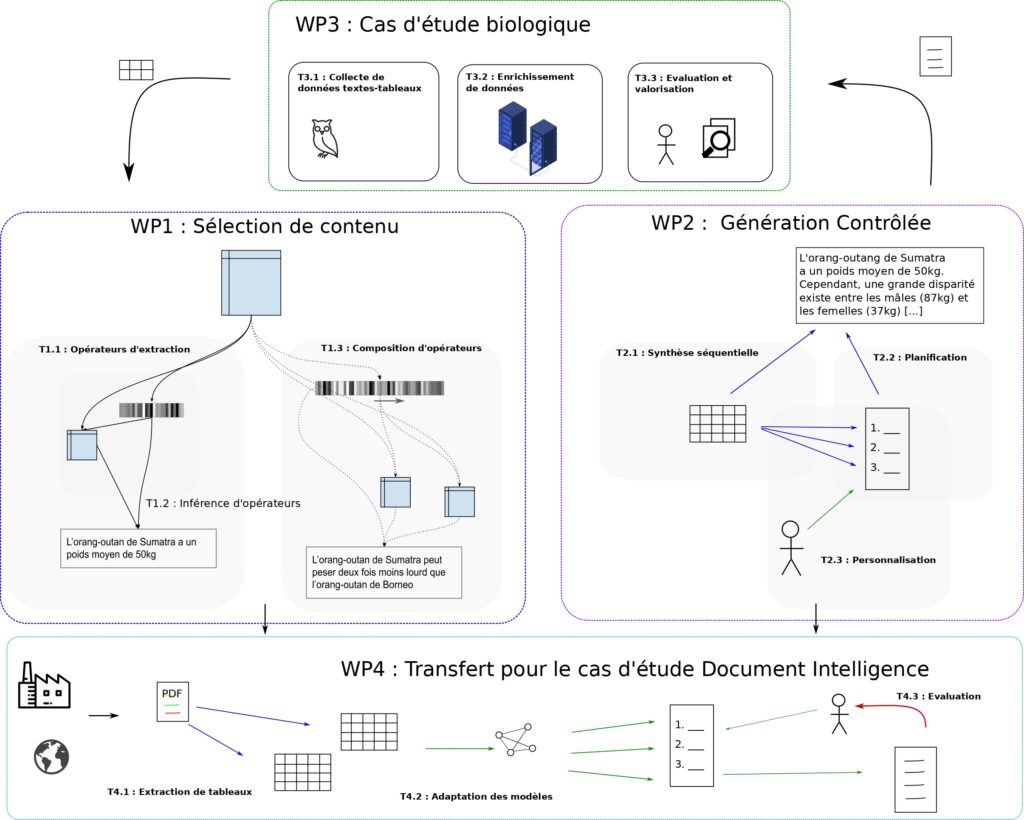
Le projet ACDC – Apprentissage Contrefactuel pour Data-to-text Contrôlé – est un projet ANR qui s’appuie sur les avancées récentes en apprentissage profond et génération de la langue pour la génération de synthèses textuelles à partir de données tabulaires. Il met l’accent sur :
- la gestion des variations de structure et de contenu des tableaux d’entrée,
- la définition et l’apprentissage d’opérateurs de sélection des informations saillantes qu’ils contiennent,
- et la personnalisation des synthèses textuelles produites.
Coordonné par Sylvain Lamprier, Chercheur à l’ISIR et Maître de Conférences en informatique à Sorbonne Université, le consortium regroupe des partenaires à fortes compétences en apprentissage, data-to-text, recherche d’information et génération du langage naturel. Il est composé de l’équipe MLIA de l’ISIR, de la start-up reciTAL, du Laboratoire d’Analyse et de Modélisation de Systèmes pour l’Aide à la Décision – LAMSADE (Université Paris Dauphine), et enfin du Muséum National d’Histoire Naturelle (MNHN – Sorbonne Université) qui apporte son expertise scientifique dans le domaine de la biologie qui est un des importants cas d’études considérés ».
Description du projet ACDC par Sylvain Lamprier, coordinateur du projet.
En quoi consiste le projet ?
Le projet ACDC – Apprentissage Contrefactuel pour Data-to-text Contrôlé – s’appuie sur les avancées en génération de la langue via des architectures neuronales, pour aborder des problématiques de synthèse textuelle d’informations contenues sous forme de données tabulaires. Nous travaillons particulièrement sur la recherche d’invariance dans les données d’entrée, la définition et l’apprentissage d’opérateurs de sélection des informations saillantes qu’ils contiennent, et la personnalisation des sorties produites. On propose de s’appuyer sur des techniques d’apprentissage profond et par renforcement, impliquant l’inférence, la manipulation et le décodage de représentations d’opérations de synthèse de contenu dans un espace sémantique continu.
Quel est l’objectif du projet ?
L’ensemble des approches récentes de data-to-text travaillent de manière supervisée, sans représentation explicite des opérateurs d’extraction qu’ils manipulent pour passer du contenu tabulaire global à la synthèse textuelle.
L’objectif du projet est de produire des espaces de représentation réguliers, encodant divers types de symétrie sémantique des opérateurs appliqués aux contenus, permettant de contrôler le mode de compression des textes générés, en fonction d’un tableau d’entrée. Ce projet se démarque car il propose de s’intéresser à l’expression des opérateurs d’extraction, afin de gagner en interprétabilité des modèles, ainsi qu’en capacité de contrôle sur les textes générés.
Notre démarche est donc de chercher à déduire les opérateurs d’extraction de contenu permettant de passer d’un tableau à un texte observé, en ayant pour but d’avoir un apprentissage robuste, qui soit à la fois fortement généralisable et contrôlable par un utilisateur. Les défis que ce projet relève sont donc : 1) l’inférence d’opérateurs d’extraction d’information dans les tableaux, 2) la gestion de l’hétérogénéité dans les données d’entrée et 3) la synthèse contrôlée de descriptions textuelles.
Quelles sont les applications possibles ?
Si l’on n’ambitionne pas dans ce projet d’atteindre un niveau humain pour interpréter des tableaux de données, nous sommes convaincus que les méthodes que l’on envisage auront un fort impact pour la communauté scientifique, car ils définissent des mécanismes d’adaptation haut-niveau pour la compréhension des données, dans les cadres applicatifs visés. Les avancées récentes en apprentissage profond (e.g. les transformeurs structurels), nous permettent d’envisager sereinement ce genre d’objectifs, qui constitueront un pas important pour la communauté vers des systèmes généralisables et personnalisables, dont l’apprentissage ne se contente pas d’imiter les sorties observées mais recherche à combiner des stratégies d’extraction complexes pour répondre à des besoins peu définis.
ACDC est un projet de recherche qui s’inscrit dans les thématiques de l’ISIR, par ses aspects traitement du langage, qui le font notamment entrer dans le cadre du projet fédérateur Langage et Sémantique. Il s’agit de faire parler les machines, pas seulement comme des machines à parole sur des contenus bien spécifiés, mais sur des aspects saillants de données d’entrée, avec sélection du contenu important et restitution synthétique. Aussi, de par ses aspects apprentissage machine et par renforcement, il paraît également entrer dans les thématiques du projet fédérateur Open-Ended Learning. On aborde ici des problématiques autour de l’apprentissage progressif, l’interprétabilité des représentations manipulées, l’apprentissage contre-factuel et le transfert de connaissances. Ses aspects « Humains dans la boucle », visant la personnalisation des contenus produits par interactions avec les utilisateurs, le placent également dans une position centrale pour les thématiques du laboratoire.
Contact référent du projet : Sylvain Lamprier, Chercheur à l’ISIR
