
Projet ACDC – Apprentissage Contrefactuel pour Data-to-text Contrôlé
Le projet ACDC s’appuie sur les avancées en génération de la langue via des architectures neuronales, pour aborder des problématiques de synthèse textuelle d’informations contenues sous forme de données tabulaires. Un accent particulier est porté sur la recherche d’invariance dans les données d’entrée, l’extraction d’opérateurs de compression haut-niveau et la personnalisation des sorties produites. On propose de s’appuyer sur des techniques d’apprentissage profond et par renforcement, impliquant l’inférence, la manipulation et le décodage de représentations d’opérations de synthèse de contenu dans un espace sémantique continu. L’objectif est de produire des espaces de représentation réguliers, encodant divers types de symétrie sémantique des opérateurs appliqués aux contenus, permettant de contrôler le mode de compression des textes générés, en fonction d’un tableau d’entrée. L’inférence d’opérateurs explicites envisagée dans ce projet permettra de mettre en place des modèles interprétables, facilitant ainsi l’analyse des synthèses produites, et la planification de rapports textuels cohérents, détaillant divers aspects saillants des données d’entrée.
Le contexte
La très grande disponibilité des données est un fait bien établi dans notre société. Que les données proviennent de textes, de traces d’utilisateurs, de capteurs ou encore de bases de connaissances, l’un des défis communs est de comprendre et d’accéder rapidement aux informations contenues dans ces données. Une des réponses à ce défi consiste à générer des synthèses textuelles des données considérées, le langage naturel présentant de nombreux avantages en terme d’interprétabilité, de compositionnalité, d’accessibilité et de transférabilité. Néanmoins, si la génération de résumés pour données textuelles est un problème pour lequel les solutions commencent à être satisfaisantes, la génération de descriptions textuelles dans un cadre plus général (par exemple, conditionnelles à des données numériques ou structurées) constitue toujours un problème particulièrement difficile. Ce problème fait référence à un champ émergent dans le domaine du traitement du langage naturel, appelé Data-to-Text, possédant de très nombreuses applications, notamment dans les domaines scientifiques, du journalisme, de la santé, du marketing, de la finance, etc.
L’ensemble des approches récentes de data-to-text travaillent de manière supervisée, sans représentation explicite des opérateurs d’extraction qu’ils manipulent pour passer du contenu tabulaire global à la synthèse textuelle. Ce projet se démarque car il propose de s’intéresser à l’expression de ces opérateurs, afin de gagner en interprétabilité des modèles, ainsi qu’en capacité de contrôle sur les textes générés. En outre, si dans un cadre figé bien défini, avec de nombreuses ressources pour la supervision, il est possible de s’affranchir de l’expression explicite de ces opérateurs, car le mode de sélection peut être implicitement adapté en fonction des sorties désirées, ce n’est plus envisageable dans un cadre plus large avec une grande hétérogénéité des données d’entrée et des attendus dans un contexte où la supervision est limitée.
Les objectifs
Notre démarche, en forte rupture avec les approches de la littérature, est donc de chercher à inférer les opérateurs d’extraction de contenu permettant de passer d’un tableau à un texte observé, en ayant pour but d’avoir un apprentissage robuste, qui soit à la fois fortement généralisable et contrôlable par un utilisateur.
Les défis que ce projet cible sont donc :
– l’inférence d’opérateurs d’extraction d’information dans les tableaux,
– la gestion de l’hétérogénéité dans les données d’entrée,
– et la synthèse contrôlée de descriptions textuelles.
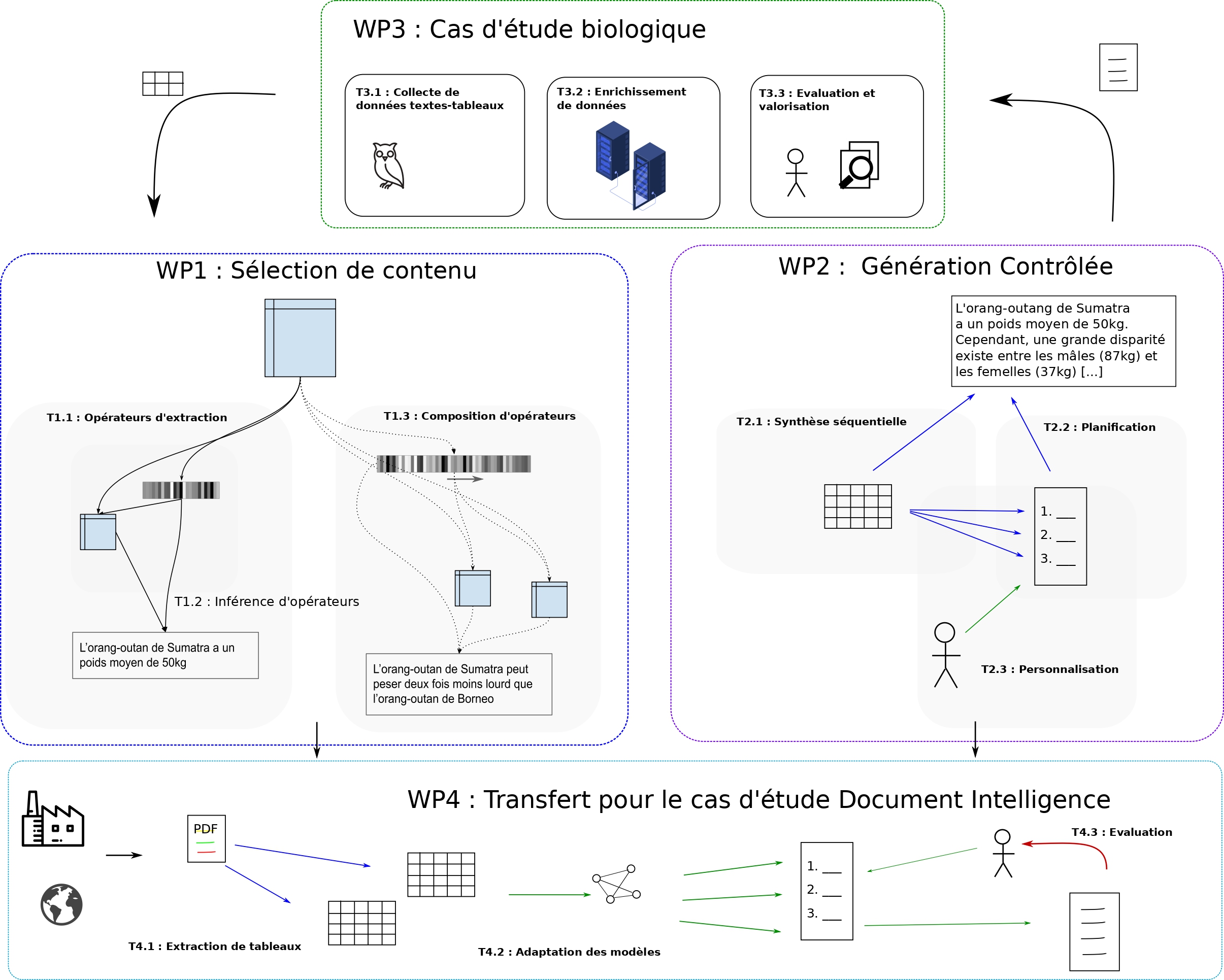
Le projet sera centré sur deux cas d’étude complémentaires, aux propriétés différentes, dans les domaines de l’analyse de données biologiques et l’analyse de documents d’entreprise. Il est articulé autour de 4 lots de travail :
- le WP1 s’intéresse à l’apprentissage d’opérateurs et l’extraction de contenu,
- le WP2 se focalise sur la planification et la personnalisation des synthèses produites,
- le WP3 concerne la production de données supervisées et l’évaluation des synthèses produites par la communauté biologique,
- le WP4 concerne des problématiques de transfert au cas d’étude financier, où les capacités de supervision sont limitées, mais les enjeux économiques considérables.
Les résultats
Si l’on n’ambitionne pas dans ce projet d’atteindre un niveau humain pour interpréter des tableaux de données, nous sommes convaincus que les méthodes que l’on envisage auront un fort impact pour la communauté scientifique, car ils définissent des mécanismes d’adaptation haut-niveau pour la compréhension des données, dans les cadres applicatifs visés. Les avancées récentes en apprentissage profond (par exemple, transformeurs structurels), nous permettent d’envisager sereinement ce genre d’objectifs, qui constitueront un pas important pour la communauté vers des systèmes généralisables et personnalisables, dont l’apprentissage ne se contente pas d’imiter les sorties observées mais recherche à combiner des stratégies d’extraction complexes pour répondre à des besoins peu définis. Pour la communauté TAL, ce genre d’avancée est cruciale pour définir divers types de systèmes guidés par les données à disposition, plutôt que d’apprendre à simplement imiter des humains. Le séquençage et la planification d’opérateurs est une proposition à fort potentiel pour dépasser les problématiques d’effondrement de postérieure ou de biais d’exposition auxquels sont très souvent confrontés les systèmes de génération de la langue naturelle. Enfin, le domaine de l’apprentissage statistique est confronté à un besoin grandissant de méthodes capables d’expliquer les décisions qu’elles prennent (xAI), portées par diverses politiques pour la protection des individus face aux machines. Un reproche très souvent fait aux architectures neuronales concerne leur opacité, ce projet apporte un élément de réponse important à cette critique, par la définition de modèles d’extraction et de verbalisation basés sur des opérateurs explicites, dont on peut interpréter la sémantique, tout en conservant de grandes capacités d’expressivité.
Pour le domaine biologique, au-delà d’une simple amélioration, par synthèse textuelle, des conditions d’accès aux informations contenues dans les tableaux de données scientifiques, le projet ACDC pourra apporter une aide à la décision importante, en pointant des informations remarquables pouvant suggérer des orientations pour des recherches à mener. Pour le domaine du Document Intelligence, la thématique du data-to-text présente des enjeux considérables pour le traitement d’informations critiques dans les secteurs de la finance, de la gestion des risques et du suivi des réglementations. L’analyse et l’interprétation des données produites par les entreprises est un enjeu crucial pour la réglementation, le suivi, l’analyse et l’amélioration du fonctionnement de structures géantes et mondialisées dont l’influence est aujourd’hui considérable. Les impacts à court terme du projet correspondent à l’intégration de méthodes efficaces pour extraire les éléments importants des tableaux de manière facilement interprétable par des auditeurs financiers, comme ceux des clients de RECITAL, qui sont confrontés à l’analyse de longs rapport pour prendre des décisions de subvention importantes en fonction des politiques courantes. À plus long terme, on peut envisager que ce genre de projet aboutira à des systèmes capables d’interpréter seuls des rapports entiers et émettre un avis circonstancié, avec prise en compte de la multi-modalité des documents analysés. Ce projet est un pas important dans ce sens et ouvre de nombreuses possibilités pour le futur.
Partenariats et collaborations
Le consortium réunit trois partenaires avec de fortes compétences en apprentissage profond et par renforcement pour la modélisation de données non structurées, le data-to-text, la recherche d’information et la génération du langage naturel.
– L’équipe MLIA de Sorbonne Université, intégrée depuis peu au laboratoire ISIR, est spécialisée en apprentissage statistique et apprentissage profond. C’est l’une des entités leader en apprentissage profond en France. Sa recherche va de la conception théorique aux développements algorithmiques, pour de nombreux domaines d’application tels que la vision par ordinateur, le traitement du langage naturel et l’analyse de données complexes. L’apprentissage de représentation, l’inférence bayésienne et l’apprentissage par renforcement pour la génération de données structurées sont au cœur de ses recherches depuis de nombreuses années.
– Le LAMSADE, de l’Université Paris Dauphine, est un laboratoire d’Informatique initialement dédié à l’aide à la décision et la recherche opérationnelle, et dont une partie des membres s’est spécialisée dans l’apprentissage profond, notamment pour le traitement et la génération de la langue.
– Le troisième partenaire du projet reciTAL est une PME dont l’activité R&D est centrée sur le traitement automatique du langage. Son implication permet de confronter les avancées du projet à des cas d’usages industriels avec enjeux très importants dans le domaine du Document Intelligence.
– Le Muséum National d’Histoire Naturelle (MNHN – Sorbonne Université) vient compléter le consortium, en y apportant sa grande expertise scientifique dans le domaine de la biologie, pour la spécification des attendus, la constitution des ressources et la validation des sorties générées.



