
Project ACDC – a french acronym for Counterfactual Learning for Controlled Data-to-text
The ACDC project – Counterfactual Learning for Controlled Data-to-text – relies on advances in language generation via neural architectures, to address problems of textual synthesis of information contained in tabular data. Particular focus is put on the search for invariance in the input data, the extraction of high-level compression operators and the personalization of the output produced. We propose to rely on deep learning and reinforcement techniques, involving inference, manipulation and decoding of content synthesis operations representations in a continuous semantic space.
Context
The high availability of data is a well-established fact in our society. Whether the data comes from texts, user traces, sensors or knowledge bases, one of the common challenges is to understand and quickly access the information contained in these data. One of the answers to this challenge is to generate textual summaries of the considered data, as natural language has many advantages in terms of interpretability, compositionality, accessibility and transferability. Nevertheless, the generation of textual descriptions is a problem that refers to an emerging field in the field of natural language processing, called Data-to-Text.
Objectives
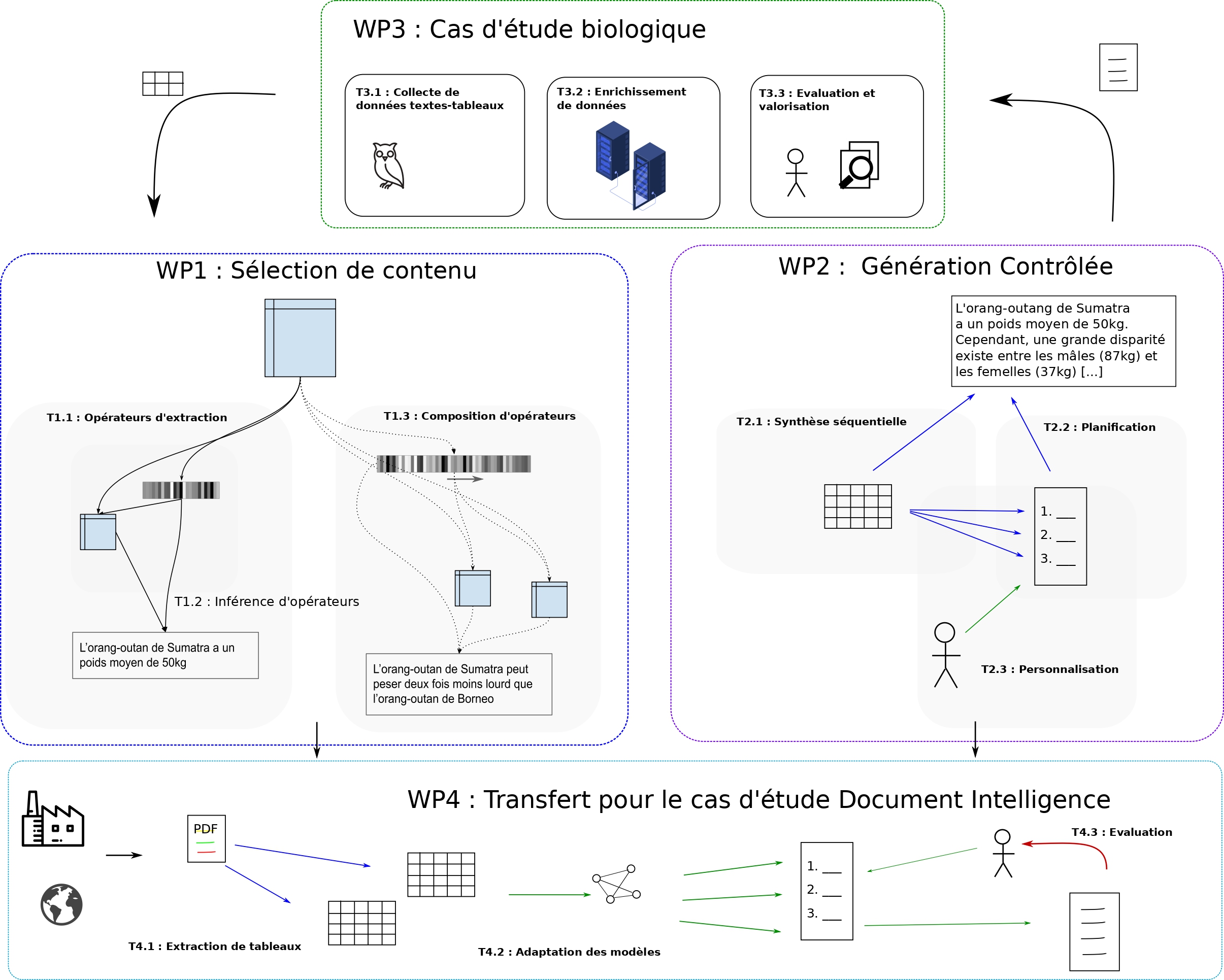
All recent data-to-text approaches work in a supervised way, without explicit representation of the extraction operators they manipulate to go from global tabular content to textual synthesis. The objective of the project is to produce regular representation spaces, encoding various types of semantic symmetry of the operators applied to the contents, allowing to control the compression mode of the generated texts, according to an input table. This project stands out because it proposes to focus on the expression of extraction operators, in order to gain in interpretability of the models, as well as in control capacity over the generated texts.
Our approach is therefore to try to deduce the content extraction operators allowing to go from a table to an observed text, with the aim of having a robust learning, which is both highly generalizable and controllable by a user. The challenges that this project targets are therefore:
– the inference of information extraction operators in tables,
– the management of heterogeneity in the input data,
– and the controlled synthesis of textual descriptions.
Results
If we don’t aim at reaching a human level to interpret data tables, we are convinced that the methods we are considering will have a strong impact for the scientific community, because they define high-level adaptation mechanisms for data understanding, in the targeted application frameworks. The recent advances in deep learning (e.g. structural transformers), allow us to serenely consider this kind of objectives, which will constitute an important step for the community towards generalizable and customizable systems, whose learning doesn’t only imitate the observed outputs but seeks to combine complex extraction strategies to meet poorly defined needs.
ACDC is a research project that is in line with the ISIR themes, by its language processing aspects, which make it part of the federative project Language and Semantics. The aim is to make machines speak, not only as speech machines on well-specified contents, but on salient aspects of input data, with selection of the important content and synthetic restitution. Also, because of its machine learning and reinforcement aspects, it also seems to fit into the themes of the Open-Ended Learning project. We address here issues around progressive learning, interpretability of manipulated representations, counter-factual learning and knowledge transfer. Its “Humans in the loop” aspects, aiming at the personalization of contents produced by interactions with users, also place it in a central position for the laboratory’s themes.
Partnerships and collaborations
The consortium brings together three partners with strong skills in deep and reinforcement learning for modeling unstructured data, data-to-text, information retrieval and natural language generation.
– The Sorbonne University MLIA team, recently integrated into the ISIR laboratory, specializes in statistical learning and deep learning. It is one of the leading entities in deep learning in France. His research ranges from theoretical design to algorithmic developments, for many application areas such as computer vision, natural language processing and complex data analysis. Representation learning, Bayesian inference and reinforcement learning for the generation of structured data have been at the heart of his research for many years.
– LAMSADE, Paris Dauphine University, is a computer science laboratory initially dedicated to decision support and operational research, and some of whose members specialize in deep learning. , especially for language processing and generation.
– The third partner of the reciTAL project is an SME whose R&D activity is centered on automatic language processing. Its involvement makes it possible to compare the progress of the project with industrial use cases with very high stakes in the field of Document Intelligence.
– The National Museum of Natural History (MNHN – Sorbonne University) completes the consortium, by bringing its great scientific expertise in the field of biology, for the specification of the expected, the constitution of the resources and the validation of the outputs generated.



