
Projet ADONIS : Asynchronous Decentralized Optimization of machiNe learnIng modelS
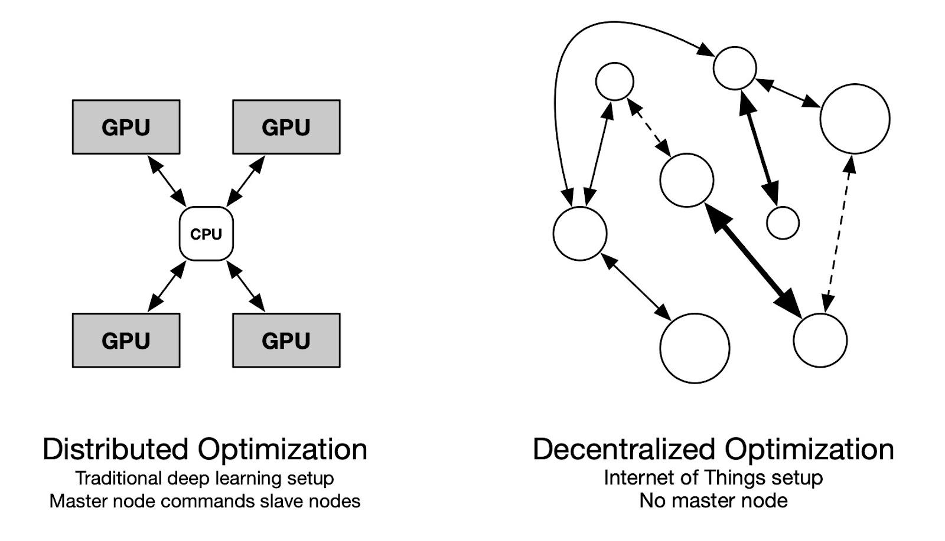
Les modèles modernes d’apprentissage en profondeur, tout en fournissant des résultats de pointe sur divers benchmarks, deviennent prohibitifs en termes de calcul. Le parallélisme est l’une des principales caractéristiques qui permet aux modèles à grande échelle d’être entraînés de bout en bout dans un délai raisonnable. En pratique, ce parallélisme revient à répliquer le modèle sur plusieurs GPU (Graphics Processing Unit) coordonnés par un CPU (Central Processing Unit). Cela garantit que toutes les opérations sont homogènes et synchrones, ce qui est nécessaire lors de la formation avec rétropropagation. Le projet ADONIS explore les moyens théoriques et pratiques de former des modèles statistiques de manière décentralisée et asynchrone. L’objectif ultime est de tirer parti de la puissance de calcul potentiellement énorme cachée dans l’Internet des objets et de la mettre à la disposition des praticiens de l’apprentissage automatique.
Le contexte
Les modèles d’apprentissage automatique modernes, généralement des modèles de langage à la pointe de la technologie, nécessitent d’utiliser des ressources informatiques considérables. Le parallélisme des données s’est concentré sur la distribution des calculs de manière centralisée, avec une gamme de GPU gérés par un CPU central. Toute cette coordination est nécessaire pour former des modèles à grande échelle, car l’algorithme de rétropropagation largement utilisé nécessite des calculs en série à travers les couches. Alors qu’un nombre croissant d’appareils informatiques devient disponible sur Internet, peu de littérature traite de la formation dans un environnement hétérogène et peu fiable. Le projet ADONIS explore les problèmes posés lors de la formation d’un modèle statistique sur un cluster de dispositifs hétérogènes avec une connectivité variable. Les membres du projet de l’ISIR ont obtenu des résultats encourageants vers l’optimisation asynchrone décentralisée. Ce projet est motivé par le fait que si la littérature couvre les algorithmes synchrones, la décentralisation et l’asynchronisme restent difficiles à étudier, en particulier dans le cas de l’apprentissage en profondeur. L’apport de l’ISIR en optimisation convexe distribuée est l’occasion d’étudier le problème d’un point de vue théorique, tandis que son expérience en apprentissage décentralisé sera utile pour souligner la pertinence pratique des apports.
Les objectifs
– Le premier objectif du projet est de dériver un cadre théorique pour rendre compte de la dynamique de formation qui doit être modélisée pour le cas d’utilisation en question. À savoir, la formation d’un modèle statistique sur un cluster d’appareils hétérogènes avec une connectivité potentiellement mauvaise et une topologie variable devrait bénéficier de l’étude de l’optimisation décentralisée asynchrone.
– De plus, pour évaluer dans quelle mesure les résultats théoriques atteignent leur objectif dans des cas d’utilisation réels, l’objectif du projet est de dériver des algorithmes compétitifs par rapport à leurs homologues traditionnels.
– Enfin, le projet propose de dériver une procédure objective facilement implémentable pour évaluer les performances de sorte que tout chercheur puisse reproduire tout résultat asynchrone dans un environnement contrôlé et le comparer à ses propres contributions.
Les résultats
Le projet ADONIS est motivé par une littérature en émergence lente mais plutôt dispersée en optimisation décentralisée asynchrone. Le PI a initié une ligne de travail sur l’apprentissage glouton qui permet de briser le verrou imposé par l’algorithme traditionnel de rétropropagation. Bien que ce travail montre des résultats prometteurs sur des jeux de données du monde réel, une première ligne de résultats théoriques est attendue de l’étude de l’optimisation convexe asynchrone décentralisée. À savoir, les taux de convergence optimaux et les conditions sur la matrice de connectivité variant dans le temps devraient être dérivés prochainement. Compte tenu de certaines connaissances théoriques sur la dynamique de formation décentralisée, l’un des objectifs est d’adapter les performances de l’apprentissage glouton découplé à des ensembles de données tels que Imagenet. Une meilleure compréhension de l’impact des astuces d’ingénierie nécessaires pour faire face à la contrainte de ressources est attendue, plus précisément sur les stratégies de quantification et l’utilisation d’un tampon de relecture. Enfin, un ensemble de procédures objectives pour évaluer les performances du modèle devrait émerger de l’expérimentation extensive prévue au cours du projet.
Partenariats et collaborations
Le projet coordonné par l’équipe MLIA est structuré autour de plusieurs organismes :
– le MILA – Institut québécois d’intelligence artificielle de Montréal,
– le centre INRIA de l’Université de Lille,
– et de l’Ecole Polytechnique de l’Université Paris-Saclay.


