
Project ADONIS : Asynchronous Decentralized Optimization of machiNe learnIng modelS
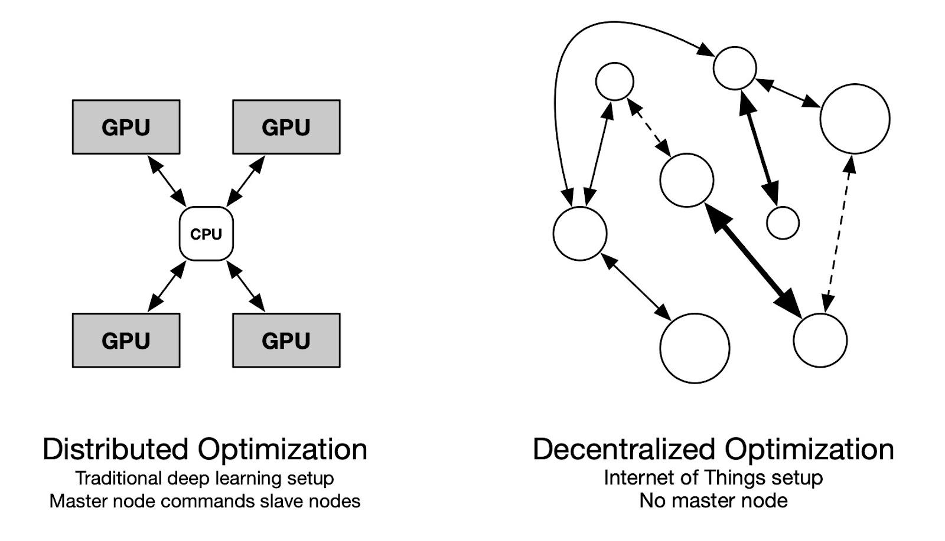
Modern deep learning models, while providing state-of-the-art results on various benchmarks, become computationally prohibitive. Parallelism is one of the main feature that allows large-scale models to be trained end-to-end within a reasonable amount of time. In practice, this parallelism amounts to replicate the model on several GPUs that are coordinated by a CPU. This ensures that all operations are homogeneous and synchronous, which is required when training with back-propagation. The ADONIS project explores theoretical and practical ways of training statistical models in a decentralized and asynchronous fashion. The very end goal is to leverage the potentially huge computing power hidden inside the Internet of Things, and make it available to machine learning practitioners.
Context
Modern machine learning models, typically state-of-the-art language models, requires high-end computing devices to be trained within a reasonable amount of time. Data parallelism has focused on distributing computations in a centralized manner, with a range of GPUs managed by a central CPU. All this coordination is necessary to train large-scale models, since the widely used back-propagation algorithm requires serial computations across layers. As a growing number of computing devices becomes available on the internet, little literature addresses training in a heterogeneous and weakly reliable environment. The ADONIS project explores the issues arising when training a statistical model on a cluster of heterogeneous devices with a varying connectivity. The project members from ISIR have obtained encouraging results toward decentralized asynchronous optimization. This project is motivated by the fact that while the literature does cover synchronous algorithms, decentralization and asynchrony remains hard to investigate, especially in the case of deep learning. The contribution of ISIR in distributed convex optimization is an occasion to investigate the problem from a theoretical perspective, while its experience in decentralized training will be useful to emphasize the practical relevance of the contributions.
Objectives
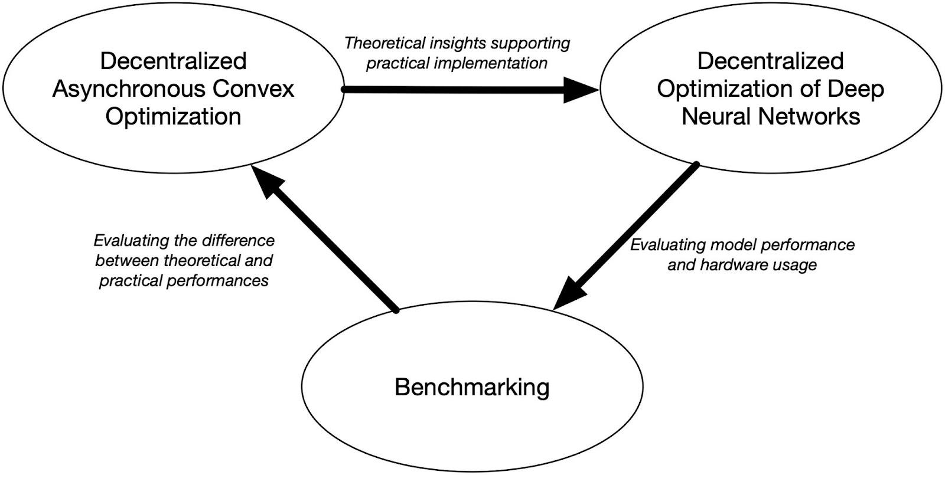
– The first objective of the project is to derive a theoretical framework to account for the training dynamics that needs to be modeled for the use case at hand. Namely, training a statistical model on a cluster of heterogeneous devices with potentially bad connectivity and varying topology should benefit from the study of asynchronous decentralized optimization. The study of decentralized convex optimization allows studying the problem from a theoretical point of view, where results such as optimal rates of convergence for an algorithm can be obtained.
– Additionally, to evaluate to which extent theoretical results meets their target in real use cases, the objective of the project is to derive algorithms that are competitive to their traditional counterpart.
– Finally, the project proposes to derive an easily implementable objective procedure to assess performances such that any researcher can reproduce any claim published during the project, and compare it to its own contributions.
Results
The ADONIS project is motivated by a slowly emerging but rather scattered literature in asynchronous decentralized optimization. The project PI has initiated a line of work about greedy learning that allows to break the backward lock imposed by the traditional back-propagation algorithm and receive growing interest in machine learning research. While this work shows promising results on real world datasets, a first line of theoretical results is expected from the study of decentralized asynchronous convex optimization. Namely, optimal convergence rates and conditions on time-varying connectivity matrix are expected to be derived soon. Given some theoretical insights on the decentralized training dynamics, one goal is to scale the performance of decoupled greedy learning to datasets such as Imagenet. A better understanding of the impact of engineering tricks needed to cope with resource constraint is expected, more precisely about quantization strategies and the use of a replay buffer. Finally, a set of objective procedure to assess model performance is expected to emerge from the extensive experimentation that is planned during the project.
Partnerships and collaborations
The project coordinated by the MLIA team is structured around:
– the MILA – Quebec Institute of Artificial Intelligence in Montreal,
– the INRIA center of the University of Lille,
– and the Ecole Polytechnique of the University of Paris-Saclay.


