
Projet SESAMS : SEarch-oriented ConverSAtional systeMS
Jusqu’à présent, dans le cadre de la recherche traditionnelle sur la recherche d’information (RI), le besoin d’information de l’utilisateur est représenté par un ensemble de mots-clés et les documents renvoyés sont principalement déterminés par leur inclusion dans ces mots-clés.
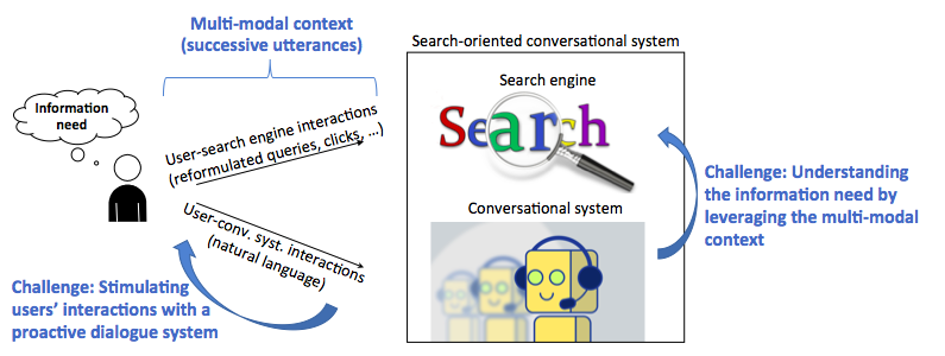
Le projet SESAMS envisage un nouveau paradigme dans la RI dans lequel l’utilisateur peut interagir avec le moteur de recherche en langage naturel par l’intermédiaire d’un système conversationnel. Nous appelons cela des systèmes conversationnels orientés recherche. Plusieurs défis importants sont sous-jacents ce nouveau paradigme, que nous aborderons dans ce projet :
– comprendre le besoin d’information de l’utilisateur en exploitant à la fois les interactions en langage naturel et le feedback implicite des utilisateurs ;
– concevoir un système proactif qui anticipe les actions des utilisateurs et leur intention de recherche en sollicitant directement l’utilisateur ;
– et évaluer ce nouveau paradigme en concevant de nouveaux cadres d’évaluation théoriques et pratiques pour les systèmes conversationnels orientés recherche et en construisant des ensembles de données à grande échelle adaptés qui permettraient d’apprendre et d’évaluer les modèles proposés.
Le contexte
La RI conversationnelle a une forte relation avec les systèmes de dialogue (chat-bots). Dans les deux cas, une conversation à plusieurs tours est établie entre l’utilisateur et le système. Cependant, l’objectif de la RI conversationnelle diffère de celui d’un système de bavardage général : l’objectif est de trouver plus facilement les informations pertinentes souhaitées d’une manière plus naturelle, plutôt que de simplement maintenir la conversation. Elle est également différente d’une conversation orientée vers une tâche dans un monde fermé, car aucun modèle basé sur un domaine en particulier domaine ne peut être construit pour la RI dans un domaine ouvert.
La RI conversationnelle est également liée aux questions-réponses (QA). En effet, la RI est généralement utilisée comme première étape des systèmes de QA pour localiser un petit ensemble de documents ou de passages candidats dans lesquels des réponses peuvent être trouvées. Les moteurs de recherche actuels incluent également les systèmes de QA en tant que sous-module, car des questions de plus en plus complètes sont soumises aux moteurs de recherche. Cependant, une grande différence entre la RI conversationnelle et la QA est qu’un besoin d’information ne peut généralement pas être décrit par une question précise. La réponse à une telle requête n’est pas non plus un type d’entité spécifique, mais toute information pertinente. Par conséquent, la RI conversationnelle doit répondre à des demandes d’utilisateurs plus larges que la QA.
Les objectifs
Nous présentons deux innovations majeures dans ce projet :
– Un nouveau paradigme de RI qui transforme le cadre bien établi de la RI ad-hoc en un cadre naturaliste. Cela implique la conception de modèles de RI capables de 1) capturer le besoin d’information des utilisateurs dans un contexte hétérogène (caractérisé par des interactions en langage naturel et le feedback implicite des utilisateurs) et 2) de rendre la session de recherche proactive dans laquelle le système anticipe ou affine activement le besoin des utilisateurs.
– De nouveaux modèles d’apprentissage automatique exploitant les interactions des utilisateurs de RI qui imposent 1) la prise en compte des particularités des actions de RI (par exemple, la reformulation des requêtes, l’expression des préférences en matière de documents, etc.) et 2) l’optimisation de l’efficacité globale de la recherche.
En outre, nous relevons les défis suivants :
– Exploitation d’un contexte hétérogène. Les différents niveaux d’interactions (utilisateur-système conversationnel et utilisateur-moteur de recherche) fournissent un contexte de session riche qu’il est crucial d’exploiter. Cependant, ces interactions sont hétérogènes puisqu’elles comprennent à la fois des interactions exprimées en langage naturel et des retours implicites collectés à travers les logs de recherche utilisateurs. Une question clé du projet est d’exploiter ce contexte hétérogène et de définir comment ces deux types d’information pourraient être pris en compte à la fois pour comprendre le besoin d’information des utilisateurs et pour engager le système dans des interactions proactives.
– Apprendre avec une petite quantité de données. Le choix méthodologique de concevoir des modèles formels basés sur l’apprentissage profond donne lieu au défi critique de la quantité de données pour l’apprentissage de modèles neuronaux profonds. C’est particulièrement le cas dans ce projet puisque le cadre adressé basé sur des systèmes conversationnels orientés recherche est un nouveau paradigme qui a émergé très récemment. Par conséquent, à notre connaissance, il n’existe pas de jeux de données impliquant simultanément les interactions des utilisateurs avec les moteurs de recherche et les systèmes conversationnels. Un autre enjeu du projet est d’intégrer des techniques basées sur l’augmentation des données ou la simulation d’utilisateurs pour apprendre les modèles que nous proposons.
– Concevoir des cadres d’évaluation adaptés. Il s’agit d’un défi majeur dans le projet puisque nous abordons un nouveau paradigme de RI qui implique un cadre plus complexe et impose la conception de nouveaux ensembles de données, protocoles, métriques et lignes de base. En tenant compte du fait que la construction d’ensembles de données à grande échelle basés sur les logs de recherche des utilisateurs réels pourrait être longue et coûteuse, ce défi impose également de simuler les journaux des utilisateurs, ce qui n’est pas évident dans un cadre aussi complexe avec des interactions hétérogènes.
Les résultats
La contribution attendue de ce projet est double, à la fois dans les domaines de l’apprentissage profond et de la RI :
– l’introduction et la mise en œuvre d’un nouveau paradigme en RI reposant sur des systèmes conversationnels orientés recherche ;
– l’introduction de l’humain dans le cadre de l’apprentissage automatique, en prenant en considération les interactions des utilisateurs avec le moteur de recherche et le système conversationnel.
Les participants attacheront une importance particulière à la publication de la contribution proposée dans des conférences et des revues de haut niveau dans les communautés de la recherche d’information (par exemple, SIGIR, CIKM, ECIR) et de l’apprentissage automatique (par exemple, NIPS, ICML, ICLR). Nous participerons également à des ateliers traitant de ce paradigme émergent (CAIR à SIGIR ou SCAI à ICTIR). Tous les codes sources des algorithmes proposés seront mis à la disposition de la communauté en open source.
Partenariats et collaborations
SESAMS est un projet développé à l’ISIR sous la direction de Laure Soulier (Maîtresse de Conférences) qui est spécialisée dans la recherche d’information (en particulier, la RI interactive) et l’apprentissage par représentation. Le projet est mené en collaboration avec des spécialistes aux compétences complémentaires :
– Ludovic Denoyer de Sorbonne Université (apprentissage par renforcement et réseaux de neurones profonds),
– Vincent Guigue de l’ISIR (apprentissage par représentation et traitement du langage naturel),
– Philippe Preux du CRIStAL/Inria Lille (apprentissage par renforcement et réseaux de neurones profonds),
– et Jian-Yun Nie du DIRO/Université de Montréal (recherche d’information et apprentissage profond).


