
Project SESAM: SEarch-oriented ConverSAtional systeMS
Until now, in traditional information retrieval (IR) research setting, the user’s information need is represented by a set of keywords and the returned documents are mainly determined by their inclusion of these keywords.
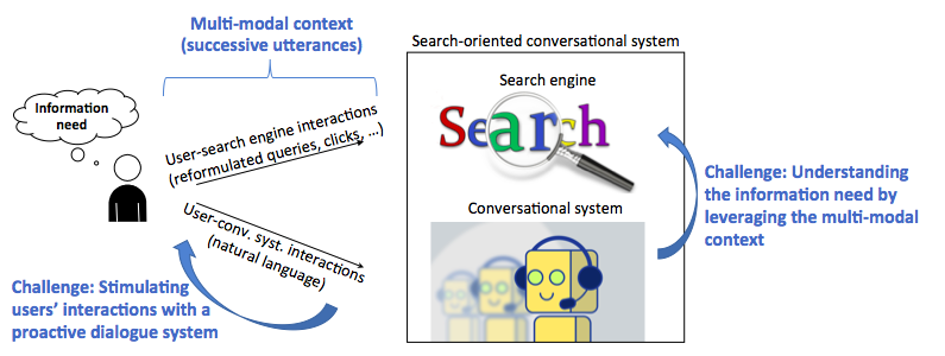
The project SESAMS envisions a novel paradigm in IR in which the user can interact with the search engine in natural language through the intermediary of a conversational system. We refer to this as search-oriented conversational systems. There are several important challenges underlying this novel paradigm, which we will address in this project:
– understanding the user’s information need by leveraging both interactions in natural language and users’ implicit feedback;
– designing a proactive system that anticipates users’ actions and users’ search intent by directly soliciting the user;
– and evaluating this novel paradigm by designing new theoretical and practical evaluation frameworks for search-oriented conversational systems and building adapted large-scale datasets that would enable the proposed models to be learned and evaluated.
Context
Conversational IR has a strong relation with general dialogue systems, e.g. chat-bots. In both cases, a multi-turn conversation is made between the user and the system. However, the purpose of conversational IR differs from that of a general chit-chat system: the purpose is to find the desired relevant information more easily in a more natural way, rather than just to keep the conversation going. It is also different from a task-oriented conversation in a closed world because no domain model can be constructed for open-domain IR.
Conversational IR is also related to question-answering (QA). Indeed, IR is generally used as the first step of QA to locate a small set of candidate documents or passages in which answers can be found. Current search engines also include QA as a sub-module, as more and more complete questions are submitted to search engines. However, a big difference between conversational IR and QA is that an information need usually cannot be described by a precise question. The answer to such a query is also not a specific type of entity, but any relevant information. Therefore, conversational IR has to deal with broader user’s demands than QA.
Objectives
We outline 2 major innovations in this project:
– A new paradigm in IR that turns the well-established ad-hoc IR setting in a naturalistic framework. This implies designing IR models able to 1) capture the users’ information need from a heterogeneous context (characterized by natural language interactions and users’ implicit feedback) and 2) make the search session proactive in which the system anticipates or actively refines users’ need.
– New machine learning models leveraging IR users’ interactions that imposes 1) considering peculiarities of IR-driven actions (e.g. query reformulation, expression of document preferences, …) and 2) optimizing the overall search effectiveness.
In addition, we address the following challenges:
– Leveraging heterogeneous context. The different levels of interactions (user-to-conversational system and user-to-search engine) provide a rich session context that is crucial to exploit. However, these interactions are heterogeneous since they include both interactions expressed in natural language and implicit feedback collected through users’ search logs. One key issue of the project is to leverage this heterogeneous context and to define how these two types of information could be considered for both understanding the users’ information need and engaging the system in proactive interactions.
– Learning with a small amount of data. The methodological choice of designing formal models based on deep learning gives rise to the critical challenge of the amount of data for learning deep neural models. This is particularly the case in this project since the addressed framework based on search-oriented conversational systems is a novel paradigm that emerged very recently. Therefore, to the best of our knowledge, there are no datasets involving simultaneously users’ interactions with both search engines and conversational systems. Another issue of the project is to integrate techniques based on data augmentation or user simulation to learn our proposed models.
– Designing adapted evaluation frameworks. This is a major challenge in the project since we address a novel IR paradigm that implies a more complex setting and imposes designing new datasets, protocols, metrics, and baselines. Taking into account the fact that building large-scale datasets based on real users’ search logs might be time-consuming and costly, this challenge imposes also simulating users’ logs which is not obvious in such a complex setting with heterogeneous interactions.
The results
The expected contribution of this project is twofold, in both deep learning and IR fields:
– Introducing and implementing a new paradigm in IR relying on search-oriented conversational systems.
– Introducing humans within the machine learning framework, by taking into consideration both users’ interactions with respect to the search engine and the conversational system.
Participants will attach particular importance in publishing the proposed contribution in high-venue conferences and journals in both information retrieval (e.g., SIGIR, CIKM, ECIR) and machine learning (e.g., NIPS, ICML, ICLR) communities. We will also participate in workshops dealing with this emerging paradigm (CAIR at SIGIR or SCAI at ICTIR). All source codes of proposed algorithms will be released to the community in open source.
Partnerships and collaborations
SESAMS is developed at ISIR under the leadership of Laure Soulier who is specialized in Information Retrieval (in particular, interactive IR) and Representation Learning. She will collaborate with specialists with complementary skills:
– Ludovic Denoyer from Sorbonne University (reinforcement learning and deep neural networks),
– Vincent Guigue from ISIR (representation learning and natural language processing),
– Philippe Preux from CRIStAL/Inria Lille (reinforcement learning and deep neural networks),
– and Jian-Yun Nie from DIRO/University of Montreal (information retrieval and deep learning).


