Ce projet fait le lien entre l’apprentissage machine et les sciences cognitives afin de permettre une meilleure collaboration entre humain et robot. L’objectif global d’OSTENSIVE est de permettre aux robots d’effectuer au mieux des tâches en collaboration avec des humains, grâce à une meilleure communication et compréhension entre les deux acteurs. En intégrant le point de vue de l’humain dans la perception, la décision et la génération d’actions, nous visons à développer des modèles capables de s’adapter aux états mentaux et aux comportements des humains.
En collaboration avec l’Inria et le LAAS, nous souhaitons développer des modèles d’apprentissage dits directs et inverses permettant d’intégrer la communication à l’action, depuis les modèles de raisonnement et de planification jusqu’à la réalisation de mouvements.

Le contexte
Lorsqu’un humain effectue une démonstration, celle-ci ne se limite pas aux objets manipulés. Elle s’accompagne également d’indices communicatifs ostensibles, tels que le regard et/ou des modulations spatio-temporelles. Ces comportements, comme les pauses, les répétitions et les exagérations, peuvent paraître sous-optimaux, mais ils sont utilisés par l’humain pour communiquer.
Les sciences cognitives abordent ce défi de la communication en action en s’inspirant du langage. La plupart des approches de l’interaction humain-robot supposent une interprétation littérale des comportements, ce qui limite fortement l’interprétation des actions et des intentions de l’autre. Il est nécessaire de disposer de modèles directs et inverses capables de générer un contenu pertinent pour l’autre (humain ou robot) et d’interpréter correctement ses actions.
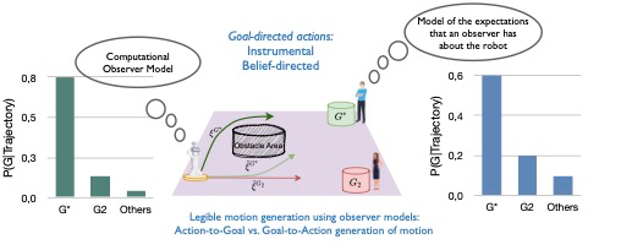
Les objectifs
Le projet OSTENSIVE vise à développer des modèles directs et inverses, basés sur l’apprentissage machine et conditionnés par des mécanismes de raisonnement relatifs à l’humain. Nos recherches couvrent un large éventail de domaines, allant du développement de modèles de haut niveau pour le raisonnement et la planification des tâches à la mise en œuvre d’une planification de mouvement de bas niveau pour une exécution physique précise.
En nous appuyant sur des approches issues des sciences cognitives, nous étudierons les situations, les indicateurs et les métriques permettant de déterminer les conditions dans lesquelles les humains interagissent avec ces modèles et en tirent profit, grâce à de nouvelles approches d’évaluation en temps réel de la prise de perspective de l’observateur. Nous développerons de nouveaux modèles capables de synthétiser des mouvements robotiques ostensifs et interactifs, ainsi que des représentations probabilistes d’actions ostensives apprises à partir de démonstrations humaines.
Les résultats
Notre objectif est d’adapter et d’étendre les protocoles expérimentaux utilisés pour étudier la cognition sociale. Les applications couvrent de nombreux secteurs, notamment la navigation sociale et la manipulation mobile en environnement partagé. Nous souhaitons garantir que les robots puissent se déplacer avec fluidité et accomplir des tâches aux côtés des humains dans des scénarios réalistes, grâce à l’intégration d’actions ostensives sur différentes plateformes robotiques.
Les travaux d’OSTENSIVE, menés à plusieurs niveaux, visent notamment à permettre aux robots de comprendre et d’interpréter correctement les intentions humaines, de définir des plans explicables pour accomplir des tâches et d’effectuer des actions de manière compréhensible pour un observateur humain.
Après approbation éthique, nous mènerons des expériences approfondies afin de valider les capacités de communication ostensive des robots auprès de participant-es novices qui devraient tirer le meilleur parti de ces capacités pour accomplir une tâche avec le robot.
Partenariats et collaborations
OSTENSIVE est une initiative collaborative entre l’ISIR, le LAAS-CNRS et l’INRIA visant à créer un cadre unifié pour l’interaction humain-robot. L’ISIR coordonne ce projet ANR OSTENSIVE (ANR-24-CE33-6907-01).
ISIR – Équipe ACIDE
– Développement de modèles d’inférence directe et inverse, avec des travaux sur la compréhension de l’intention humaine et la prédiction de l’impact des actions d’un agent sur la perception humaine.
– Référent OSTENSIVE : Mohamed Chetouani
INRIA (Nancy) – Équipe LARSEN
– Étude des mouvements ostensifs, grâce à des outils tels que les primitives de contrôle et les politiques robotiques.
– Référente OSTENSIVE : Serena Ivaldi
LAAS-CNRS (Toulouse) – Équipe RIS
– Réalisation de méthodes de planification prenant en compte la présence des humains, par l’utilisation de la théorie de l’esprit et de la prise de perspective d’un observateur externe.
– Référent OSTENSIVE : Rachid Alami
L’étude a examiné les émotions suscitées par l’écoute de sons correspondant à l’enregistrement de gestes tactiles affectifs organiques, c’est-à-dire réels (par exemples, caresse de l’avant-bras, effleurement de la joue). Les gestes ont été enregistrés sur d’autres personnes que ceux qui les écoutent et ils sont présentés de manière isolée. L’étude a été motivée par la diminution constante de l’engagement dans le toucher interpersonnel, en grande partie due à la numérisation de l’expérience humaine. Cette diminution a montré des effets délétères sur les individus et les prive (tant les personnes qui touchent que celles qui sont touchées) des nombreux bénéfices du toucher affectif, notamment la régulation émotionnelle. Il devient donc particulièrement pertinent d’étudier des moyens alternatifs de transmettre les bénéfices du toucher affectif, par exemple via différentes modalités sensorielles. Ici, le son constitue une option intéressante compte tenu de la relation étroite entre les ondes auditives et tactiles.
Le contexte
L’étude s’inscrit dans le cadre du projet ANR MATCH Audio-Touch. Elle prolonge la première étude de ce projet en investiguant les réponses émotionnelles aux sons de toucher affectif au-delà de la simple identification, et en examinant l’influence du sens (meaning) et des attentes préalables concernant ce à quoi devrait ressembler des toucher sonores selon les participants et participantes.
Les objectifs
L’objectif principal de l’étude est d’examiner l’espace émotionnel des indices auditifs produits par le toucher affectif organique, présenté isolément, ainsi que les dimensions qui l’influencent. Ces sons peuvent-ils évoquer des émotions positives ? Existe-t-il des variables qui renforcent ces émotions ? Pour ce faire, nous avons mené cinq expériences afin de dissocier les réponses émotionnelles au toucher affectif organique et d’identifier les variables clés qui les modulent.
Nous avons extrait des sons générés par des gestes tactiles affectifs organiques en recrutant 14 couples engagés dans une relation et en enregistrant les gestes tactiles qu’ils pratiquent habituellement, ce qui a produit une grande variété de sons de toucher affectif. L’objectif de recourir à des gestes spontanés, plutôt qu’à des gestes prédéfinis, était d’évaluer plus écologiquement le traitement psychologique du toucher affectif et de ses indices multisensoriels, et d’en saisir les nuances.
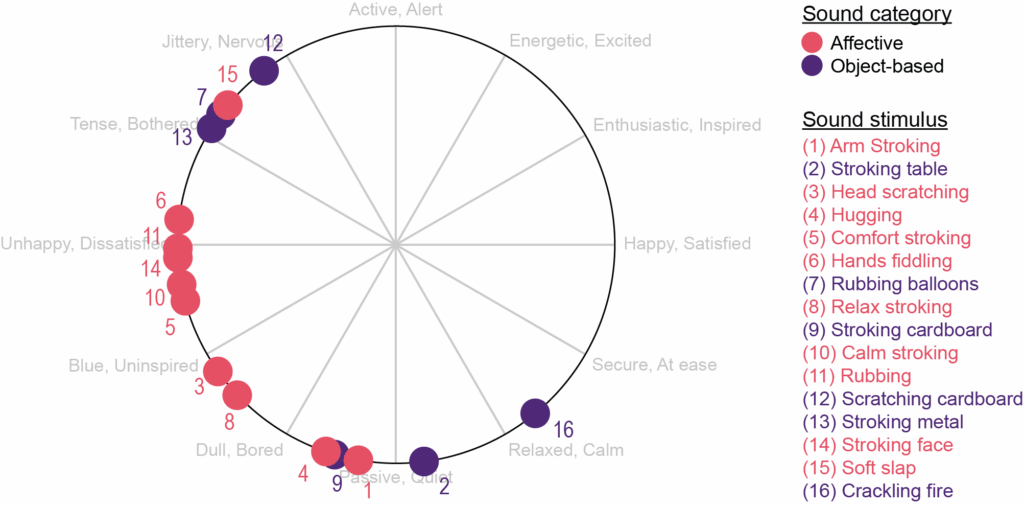
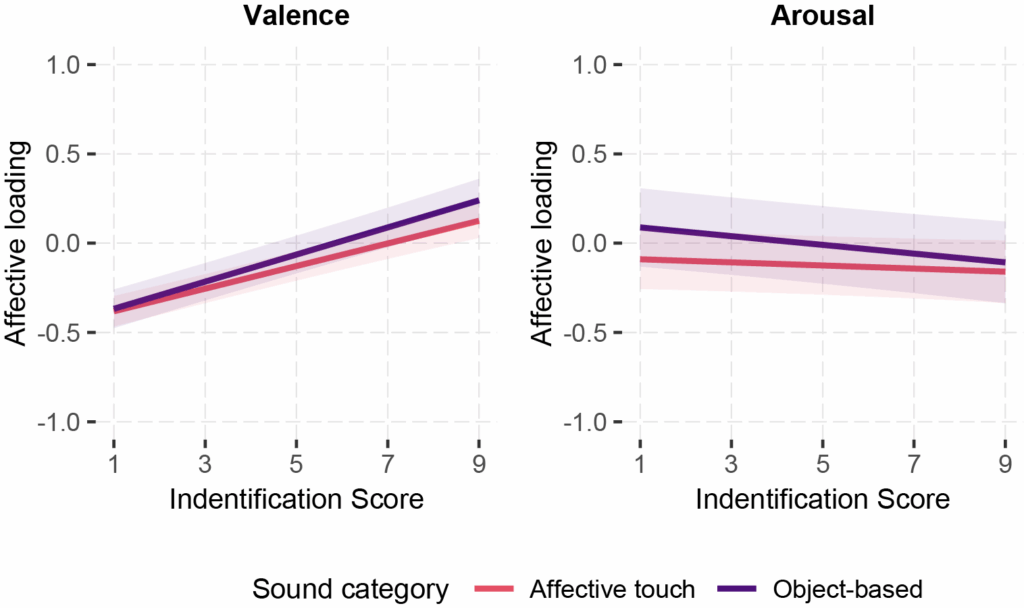
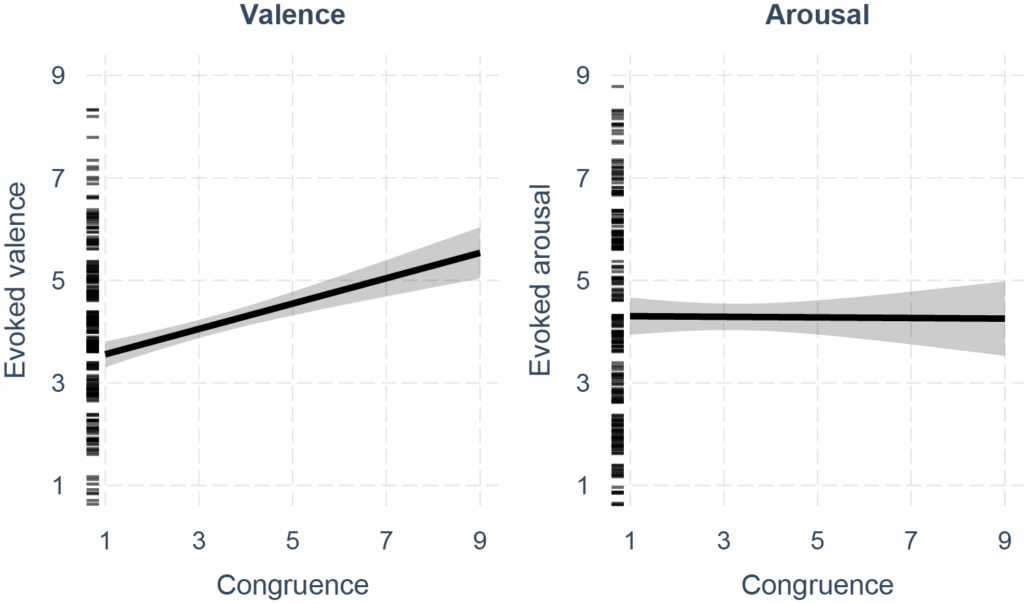
Les résultats
Globalement, nous avons constaté que les seuls sons du toucher affectif suscitaient des réponses émotionnelles caractérisées par une positivité réduite et un niveau d’activation (arousal) légèrement plus élevé, et que les individus avaient une capacité limitée à identifier le toucher affectif à partir d’indices auditifs. En résultats important, nous avons montré que le sens compte. Le fait de présenter explicitement les sons comme relevant d’un toucher affectif organique, plutôt que de ne fournir aucun contexte ou de les présenter comme des interactions avec des objets, augmente la valence qu’ils évoquent. De plus, plus les sons correspondent à ce que les individus s’attendaient initialement à entendre comme sons de toucher affectif, plus la valence suscitée par ces sons est élevée, bien que les personnes disposent de connaissances et d’attentes limitées concernant les sons du toucher affectif. Notre étude est la première à examiner l’espace émotionnel de la dimension auditive du toucher affectif, un champ émergent en soi, riche en perspectives.
D’un point de vue appliqué, nos résultats peuvent servir à renforcer les réponses émotionnelles à des stimuli non tactiles dans le cadre d’interactions interpersonnelles. Par exemple, imaginez la narration d’une histoire émotionnelle incluant des interactions tactiles affectives entre les personnages : les sons de touchers organiques pourraient être utilisés pour amplifier les émotions que ces interactions visent à transmettre. Une autre possibilité est l’amélioration des réponses émotionnelles lors d’interactions numériques avec des agents humains et non humains (par exemples, robots, agents d’IA anthropomorphisés). Il importe toutefois de souligner que des recherches supplémentaires sur le toucher multisensoriel et ses applications sont nécessaires.
Partenariats et collaborations
L’étude s’inscrit dans le cadre de l’ANR Match, dans lequel nous collaborons avec Catherine Pelachaud (ISIR), Ouriel Grynszpan (Université Paris-Saclay) et Indira Thouvenin (UTC Compiègne). Nous avons aussi collaboré avec le Behavioural Lab d’INSEAD–Sorbonne Université, qui nous a aidés à recruter les 14 couples et a mis à disposition les infrastructures physiques nécessaires à l’enregistrement des stimuli expérimentaux.
Le projet Haptivance vise à créer une nouvelle génération de surfaces tactiles capables de produire des sensations de force et de mouvement sous le doigt. Il est né du constat que les technologies haptiques actuelles sur écrans sans bouton physique restent peu précises et ne permettent pas de véritable retour kinesthésique, contrairement aux dispositifs robotiques très coûteux.
En s’appuyant sur les travaux de thèse de Thomas Daunizeau à l’ISIR (avec Sinan Haliyo et Vincent Hayward) sur les métamatériaux acoustiques, le projet veut structurer la propagation des vibrations pour localiser le toucher, générer des sensations directionnelles ou similaire à des touches/boutons physiques sur des surfaces totalement lisses.
Le développement de cette technologie ouvre pour nous une avancée pour l’amélioration de dispositifs médicaux pour satisfaire un usage intuitif et sécurisé tout en facilitant le nettoyage et la stérilisation en éliminant les boutons mécaniques difficiles à nettoyer et propices au développement de micro-organisme dans les milieux hospitaliers.
Le contexte
Le retour haptique est aujourd’hui omniprésent : smartphones, consoles de jeu, interfaces industrielles ou médicales. Pourtant, ces systèmes ne génèrent qu’une vibration globale, impossible à localiser finement, et ne peuvent pas exercer de force nette sur le doigt. Cela limite fortement leur intérêt dans des situations où la précision est critique : chirurgie robotique, automobile, dispositifs d’accessibilité. Dans ces environnements, l’utilisateur doit souvent regarder l’écran pour valider ses actions, augmentant la charge cognitive et le risque d’erreur.
Si on prend le cas des interfaces hospitalières, elles reposent encore largement sur des boutons mécaniques, difficiles à stériliser et sujets à l’usure, alors que les surfaces tactiles lisses sont plus adaptées aux contraintes d’hygiène. Cependant, ces écrans sont dépourvus de retour tactile assez informatif, obligeant les soignants à vérifier visuellement leurs actions, augmentant ainsi la charge cognitive et le risque d’erreur. Les alternatives existantes restent coûteuses, complexes ou peu compatibles avec les écrans. C’est notamment dans ce contexte, qu’il existe un besoin fort d’un toucher riche, localisé et compatible avec des surfaces interactives.

Les objectifs
L’objectif principal du projet, dans un premier temps, est de mettre au point un démonstrateur fonctionnel d’une surface interactive produisant un retour tactile localisé et directionnel.
Scientifiquement, le projet cherche à maîtriser la propagation des ondes ultrasoniques progressives en surface grâce à des métamatériaux acoustiques. C’est-à-dire être capable de générer une force nette sur le doigt sans actinnement exterieur, mais en faisant résonner la surface. Pour cela, il nous faut encore comprendre le dimensionnement de nos métamatériaux afin de créer une force homogène sur toute la surface. Et d’étudier quelles sensations haptiques seront les plus convaincantes en lien avec un affichage visuel et la position du doigt en temps réel.
Le POC devra permettre de ressentir des boutons, arêtes, mouvements ou guidages sur des écrans tactiles. À terme, le projet vise une technologie industrialisable pour fournir une solution haptique à des fabricants d’écrans.
Les résultats
Les premiers résultats expérimentaux ont confirmé la possibilité de générer des ondes progressives sur une surface, créant un déplacement perceptible sous le doigt. Le projet doit maintenant étendre et amplifier cet effet, de manière stable et efficace. Le démonstrateur visuo-haptique attendu en fin de projet permettra des interactions multitactiles : clics, glissements directionnels, guidage du doigt, etc.
Les applications principales visées sont celles en milieu hospitalier : les interfaces chirurgicales, les moniteurs et les systèmes d’imagerie au bloc opératoire, les dispositifs médicaux en réanimation ou des interfaces de téléopération robotique.
Dans un autre registre, certains contextes demandent eux aussi beaucoup d’attention visuelle sur la tâche principale et sont sensibles aux distractions : c’est le cas de la conduite, pour laquelle les tableaux de bord automobiles composés d’écrans tactiles, uniquement, pourraient permettre une interaction bien plus sûre grâce au retour haptique.
Globalement, cette technologie veut permettre de réduire l’attention visuelle nécessaire pour une tache de manipulation d’interface, en étant facilement nettoyable, d’améliorer la précision des gestes et d’enrichir l’expérience utilisateur, y compris pour l’accessibilité des personnes en situation de handicap.
Partenariats et collaborations
– Programmes d’accompagnement : PUI Alliance Sorbonne Université – MyStartUp programme, i-PhD Bpifrance
– ISIR, Institut CNRS Sciences Informations / CNRS Innovation pour l’accompagnement aux demandes de financement
– SATT Lutech – Valorisation, brevet, maturation
– AP-HP – Hub Innovation & tiers-lieu BOPEx, tests et co-conception avec personnels de santé
Lexio Robotics est une solution logicielle dédiée à la manipulation robotique dans des contextes variés, fondée sur une approche d’IA génétique. Elle permet la reprogrammation en langage naturel et l’acquisition autonome de compétences par les robots, levant ainsi les limitations actuelles de la robotique et ouvrant une nouvelle ère pour la robotique B2C et B2B. Ce projet de startup est né à l’ISIR dans le cadre d’une collaboration de recherche sur l’apprentissage robotique en milieu ouvert. L’équipe explore actuellement de nombreux cas d’usage à fort potentiel, allant de la fabrication et de la logistique aux services et à l’usage domestique.

Le contexte
Le projet s’inscrit en réponse à deux problèmes majeurs :
De nombreux secteurs de l’économie peinent à recruter pour des tâches de manipulation répétitives. Industrie manufacturière, logistique, hôtellerie, aide à la personne… de nombreux professionnels s’inquiètent pour la pérennité de leur activité, parfois critique pour la souveraineté du pays.
La robotique ouvre des perspectives pour assurer la continuité de la production dans ces activités. Cependant, malgré les récentes avancées, les robots ne sont pas encore dotés de réelles capacités d’adaptation. Dans les vidéos spectaculaires diffusées sur Internet, les robots sont presque toujours téléopérés. Le manque de solutions permettant aux robots de réaliser des tâches de manipulation avec des capacités d’adaptation demeure un obstacle majeur.
Les récentes avancées en intelligence artificielle laissent entrevoir des perspectives de levée de ces verrous, entraînant une effervescence aussi bien dans le monde académique que dans le monde économique.
Les objectifs
Ce projet de start-up, fortement ancré dans la recherche académique, vise à doter les robots de capacités de manipulation d’objets en environnement ouvert.
Il s’agit en particulier :
– De permettre à des robots d’apprendre rapidement à résoudre de nouvelles tâches avec fiabilité ;
– De permettre à des utilisateurs non experts de se servir des robots et de les reprogrammer par la parole ;
– De développer des solutions logicielles respectant les standards de qualité, d’éthique et de sécurité, afin de permettre le déploiement de robots en environnements ouverts pour des tâches de manipulation.
Les résultats
Les applications possibles couvrent de très nombreux secteurs, allant de la production (industrie manufacturière, logistique) aux services (hôtellerie, aide à la personne).
Le projet s’appuie sur l’état de l’art de l’intelligence artificielle pour la robotique de manipulation, et en particulier sur une série de travaux portant sur les algorithmes génétiques, visant à permettre la reprogrammation aisée des robots.
Ces travaux permettent à un robot d’apprendre automatiquement de nouvelles compétences de manipulation au sein d’une scène simulée représentant un environnement opérationnel donné.
Les compétences ainsi acquises – saisie et dépôt d’objets, insertion, empilement, etc. – peuvent ensuite être transférées avec succès sur des robots physiques.
Par ailleurs, les données générées peuvent servir de ressources pour affiner des modèles fondamentaux sur de nouvelles tâches.
Partenariats et collaborations
Le fond scientifique de ce projet s’appuie sur plusieurs collaborations :
– Le projet franco-allemand Learn2Grasp ;
– Le réseau d’excellence européen de l’IA pour la robotique, euROBIN ;
– Le projet européen pour l’apprentissage ouvert, PILLAR ;
– Une collaboration avec l’Imperial College de Londres.
La start-up a vocation à maintenir de forts liens avec la sphère académique, notamment avec l’ISIR et Sorbonne Université. Des discussions sont en cours pour en définir les contours.
L’approche du projet Audio-touch combine les résultats de la recherche sur le toucher social et sur la sonification du mouvement, ce qui permet d’extraire certaines caractéristiques significatives des interactions tactiles et de les convertir en sons. Dans les études expérimentales du projet, les participant-es qui écoutaient les stimuli audio-touch peau à peau ont associé avec précision les sons à des gestes spécifiques et ont identifié de façon cohérente les intentions socio-émotionnelles sous-jacentes aux touchers convertis en sons.
De plus, les mêmes mouvements ont été enregistrés avec des objets inanimés, et des expériences supplémentaires ont révélé que la perception des participant-es était influencée par les surfaces impliquées dans les interactions tactiles (peau ou plastique). Cette approche audio-touch pourrait être un tremplin pour donner accès à l’expérience ineffable du toucher social à distance, avec des agents humains ou virtuels.
Le contexte
Le toucher est la première modalité sensorielle à se développer, et le toucher social a de nombreux effets bénéfiques sur le bien-être psychologique et physiologique des individus. Les situations de carences en touchers sociaux accentuent les sentiments d’isolement, d’anxiété et le besoin de lien social. Face à ce constat, il devient urgent d’explorer des moyens de recréer, à distance, les effets bénéfiques du toucher affectif.
Ce projet est né de cette urgence, mais aussi d’une observation fondamentale : le toucher et l’audition partagent une base physique commune, celle des vibrations. Les études de sonification ont déjà montré qu’il était possible de traduire des mouvements et leurs propriétés en sons. Il devient alors envisageable de traduire certaines caractéristiques des interactions peau à peau en signaux auditifs perceptibles. De la convergence entre ce besoin de lien tactile à distance et les similitudes physiques entre toucher et son est né le projet Audio-touch, qui vise à transmettre les informations du toucher affectif via des sons.
Les objectifs
L’objectif principal de cette recherche est d’étudier les possibilités offertes par l’audio-touch : peut-on convertir du toucher peau à peau en sons ? Plus précisément, l’équipe a ensuite déterminé expérimentalement quelles informations du toucher social les stimuli audio-touch pouvaient communiquer aux personnes qui les écoutent : peut-on reconnaître différents types de gestes du toucher dans nos stimuli audio-touch ? peut-on reconnaître différentes intentions socio-affectives sous-jacentes à ces gestes du toucher sonifié ? la surface sur laquelle le toucher a lieu (peau versus objet inanimé) influence-t-elle ces perceptions ?
Les résultats
Les quatre expériences menées dans cette étude montrent que les gestes tactiles sociaux, leurs intentions socio-émotionnelles et la surface touchée (peau vs plastique) peuvent être reconnus uniquement à partir des sons audio-touch créés. En effet, les résultats montrent que :
– les participant-es ont correctement catégorisé les gestes (expérience 1),
– les participant-es ont identifié les émotions transmises (expérience 2),
– leur reconnaissance a été influencée selon la surface sur laquelle le toucher avait lieu (expériences 3 et 4).
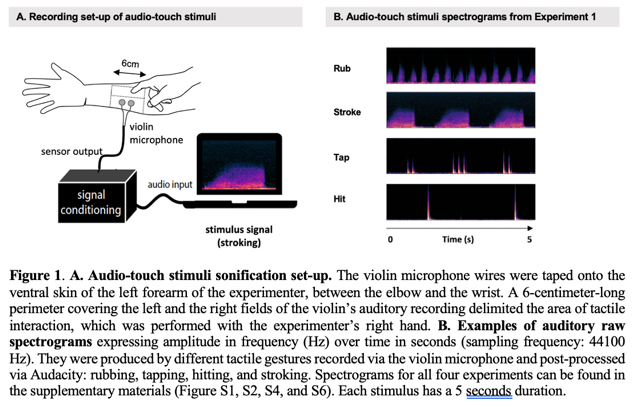
Ces résultats ouvrent des perspectives à l’intersection des domaines de l’haptique et de l’acoustique, le projet Audio-touch se situant précisément à la croisée de ces deux champs, tant par sa méthodologie de captation des gestes tactiles que par son intérêt pour la perception humaine des signaux sonores issus du toucher. Ils s’inscrivent également dans les recherches en interaction humain-machine, et suggèrent que des sons issus du toucher social pourraient enrichir les expériences multisensorielles, notamment dans les interactions avec des agents sociaux virtuels.
Partenariats et collaborations
Le projet est une collaboration entre :
– Alexandra de Lagarde, doctorante de l’équipe ACIDE de l’ISIR,
– Catherine Pelachaud, directrice de recherche CNRS de l’équipe ACIDE de l’ISIR,
– Louise P. Kirsch, maîtresse de conférence INCC, à l’Université Paris Cité, et ancienne post-doctorante de l’équipe Piros à l’ISIR,
– Malika Auvray, directrice de recherche CNRS de l’équipe ACIDE de l’ISIR.
De plus, pour la partie acoustique liée au projet, l’étude a bénéficié de l’expertise de Sylvain Argentieri pour la partie enregistrements et de Mohamed Chetouani pour la partie traitement du signal.
Il s’inscrit également dans le cadre du programme ANR MATCH, qui explore la perception du toucher dans les interactions avec des agents virtuels, en partenariat avec HEUDIASYC (UTC) et le LISN (Université Paris Saclay).
Projet MAPTICS : Développement d’un cadre multisensoriel pour l’haptique
Le projet MAPTICS vise à développer un nouveau cadre haptique multimodal en caractérisant la façon dont les utilisateurs et utilisatrices intègrent les indices multisensoriels dans une perception unifiée et quelles facettes du toucher sont les plus essentielles à reproduire dans les applications virtuelles et numériques.
Dans ce but, il étudie le potentiel du rendu vibro-frictionnel et du renforcement multisensoriel pour créer l’illusion d’objets en 3D sur l’écran d’une nouvelle interface haptique multimodale et explore la manière dont l’haptique peut être intégrée dans la prochaine génération d’interfaces multisensorielles qui combinent un retour d’information tactile, auditif et visuel haute-fidélité. Cette recherche permettra finalement de créer et d’évaluer de nouvelles applications multimodales d’IHM pour les utilisateurs-utilisatrices classiques ainsi que ceux souffrant de déficiences sensorielles.

Le contexte
Les interfaces actuelles des IHM fournissent généralement un retour d’information visuel et auditif de haute résolution. En revanche, le retour haptique est souvent absent des écrans, malgré des produits commerciaux récents tels que le moteur Taptic sur les smartphones haut de gamme d’Apple. Bien que l’interaction multimodale ait le potentiel d’améliorer l’acceptabilité, l’efficacité de l’interaction et d’être plus inclusive pour les personnes souffrant de déficiences sensorielles, son développement est entravé par l’absence de cadre multisensoriel pour intégrer le retour haptique aux signaux audiovisuels, ainsi que par la faible fidélité de l’haptique par rapport à la vision et à l’audition dans les affichages.
Par conséquent, l’avenir du retour d’information multisensoriel est confronté aux défis de la conception d’un retour d’information haptique haute-fidélité et de l’utilisation efficace des principes cognitifs qui sous-tendent la perception multisensorielle. Dans ce contexte, de nouvelles stratégies de rendu et des dispositifs plus performants qui intègrent un retour haptique riche au rendu audiovisuel haute résolution sont de plus en plus envisagés.
Les objectifs
– Développer un écran interactif capable de fournir un retour haptique vibrotactile combiné avec un retour d’effort, ainsi que des capacités audiovisuelles à haute résolution. Le défi consiste à créer une interface tactile active offrant un retour d’information plus riche que les dispositifs scientifiques et commerciaux actuels.
– Développer un cadre versatile pour le rendu multisensoriel et l’utiliser pour comprendre les processus cognitifs en jeu lors du traitement des données multisensorielles. Pour ce faire, nous utilisons la plateforme multisensorielle développée dans MAPTICS pour manipuler la congruence entre les entrées sensorielles auditives, visuelles et tactiles dans le but d’étudier le renforcement ou la perturbation des représentations cognitives.
– Nous nous appuyons sur les deux sous-objectifs précédents pour construire une interface utilisateur-utilisatrice avec un retour haptique multisensoriel renforcé à haute résolution. Avec cette nouvelle interface, nous étudierons des scénarios liés à la navigation dans des cartes interactives multisensorielles ou à l’utilisation de boutons virtuels.
Les résultats
La stimulation vibrotactile et la lubrification ultrasonique simultanées n’ont pas encore été étudiées, bien qu’elles puissent potentiellement lever de sérieuses limitations technologiques actuelle, telles que : l’incapacité des vibrations ultrasoniques à fournir un retour d’information convaincant lorsque le geste de l’utilisateur ou l’utilisatrice n’implique pas de mouvement du doigt, ou la difficulté de créer des formes virtuelles avec des vibrations mécaniques.
Une meilleure compréhension de la mise en œuvre conjointe des deux types de retour d’information permettra de créer des dispositifs haptiques plus efficaces et plus convaincants. Par ailleurs, le rendu haptique vibrotactile et le rendu haptique par friction sont actuellement des sujets de recherche distincts.
Après Maptics, nous espérons que la recherche haptique étudie de plus en plus ces deux techniques complémentaires afin de développer efficacement un rendu tactile plus intégré. En outre, le projet fournira un nouvel outil expérimental multisensoriel qui permettra une étude et une compréhension plus poussées des mécanismes sous-jacents de l’intégration sensorielle.
Partenariats et collaborations
Le projet MAPTICS est un projet ANR (Agence nationale de la recherche), mené en partenariat avec Betty Lemaire-Semail du laboratoire L2Ep de l’Université de Lille.
Le projet « Apprentissage Robotique pour la Manipulation Mobile et l’Interaction Sociale » s’inscrit dans un contexte où les robots autonomes doivent répondre à des besoins complexes, tels que l’interaction physique et sociale dans des environnements réels. Les défis actuels incluent l’adaptabilité aux situations imprévues, la collaboration fluide avec les humains, et la capacité à naviguer dans des environnements variés. Ces enjeux sont particulièrement cruciaux dans des domaines tels que les services domestiques, la logistique et l’agriculture.
Le contexte
Le contexte de l’ISIR permet d’apporter une expertise unique dans les aspects multidisciplinaires de l’apprentissage robotique, incluant le contrôle, l’apprentissage automatique et l’interaction sociale. L’ISIR met également à disposition ses plateformes robotiques avancées, telles que Tiago, Miroki, Pepper et PR2, spécialement conçues pour la manipulation mobile. Avec ces ressources et son approche innovante, le laboratoire joue un rôle crucial dans le développement de robots autonomes, capables de relever les défis sociétaux et industriels, tout en renforçant les collaborations au sein de la communauté européenne de la robotique.

Les objectifs
Le projet vise à atteindre un niveau d’autonomie élevé pour les robots dans des environnements complexes. L’un des objectifs principaux est l’utilisation des modèles de langage (LLMs) pour la planification robotique, l’identification des affordances et la saisie d’objets, permettant une meilleure compréhension et interaction avec le monde réel. En parallèle, le projet cherche à développer un système intégré combinant des modèles de perception à la pointe de la technologie, notamment basés sur la vision, et des méthodes avancées de contrôle. Par exemple, la technique de QD grasp (Quality-Diversity), développée à l’ISIR, est un pilier de cette approche.
L’objectif global est de créer des robots capables d’interagir de manière autonome, efficace et fiable avec leur environnement, tout en exploitant les synergies entre perception, contrôle et apprentissage automatique pour des applications dans des domaines variés.
Les résultats
Le projet a permis l’intégration de la pile QD-grasp sur le robot Tiago, incluant des fonctionnalités avancées telles que la génération de saisies, la détection, la segmentation et l’identification d’objets. De plus, une planification basée sur les modèles de langage (LLMs) a été intégrée, permettant au robot de comprendre et d’exécuter des tâches exprimées en langage naturel par des utilisateurs humains. Ces développements améliorent considérablement l’interaction humain-robot et la capacité des robots à évoluer dans des environnements complexes.
Le projet a également participé à la compétition annuelle euROBIN, où il a démontré ses avancées en matière de modularité et de transférabilité des compétences robotiques. Nous partageons continuellement nos composants développés pour la manipulation mobile avec la communauté, contribuant ainsi à l’évolution collective des technologies robotiques et à leur application à des défis concrets.
Partenariats et collaborations
Ce projet est une initiative interne à l’ISIR, regroupant des expertises issues de différents axes de recherche et de développement. Il s’appuie notamment sur les contributions de :
– l’équipe ASIMOV (sur l’aspect manipulation et interaction robotique),
– l’équipe ACIDE (sur l’aspect cognition et interaction,
– et de l’axe prioritaire Ingénierie des systèmes intelligents.
Ces collaborations internes permettent de mobiliser des compétences complémentaires en apprentissage robotique, perception, contrôle et interaction sociale, renforçant ainsi la capacité de l’ISIR à relever des défis scientifiques et technologiques majeurs.
Projet Open A-Eye : Le retour kinesthésique pour guider les personnes malvoyantes
L’originalité du dispositif de l’équipe A-Eye est de fournir un guidage kinesthésique qui se veut plus intuitif que les retours audio et/ou vibrants proposés dans les solutions du commerce. Cela permet de réduire la charge cognitive nécessaire pour suivre les informations. Ce dispositif, les réglages fins de la rétroaction qu’il propose ainsi que toutes les autres solutions permettant de répondre aux différents challenges du Cybathlon* ont été co-conçus avec l’aide de notre « pilote ». L’équipe A-Eye place en effet la co-création au cœur du processus, travaillant avec des associations, des experts en accessibilité et la pilote aveugle d’A-Eye. L’objectif est de créer une solution ergonomique, accessible, facile à utiliser et adaptée à la vie quotidienne.
Le dispositif de l’équipe A-Eye intègre des technologies de pointe, combinant le retour kinesthésique intuitif à des fonctionnalités de vision par ordinateur et d’intelligence artificielle. Le dispositif portable, sous forme d’un harnais/sac à dos offre une navigation précise, mimant l’interaction avec un guide humain et offrant ainsi une expérience intuitive.
*Le Cybathlon est un évènement qui a lieu tous les 4 ans et organisé par l’École polytechnique fédérale de Zurich qui met au défi des équipes du monde entier autour de 8 épreuves. L’objectif est de démontrer les progrès technologiques d’assistance dans l’accomplissement des tâches de la vie quotidienne de personnes en situation d’handicap.
Le contexte
Il est connu que le guidage le moins fatiguant dans un environnement nouveau est celui fourni par une personne formée aux techniques de guide. Ce guidage est bien plus intuitif et nécessite ainsi beaucoup moins de concentration qu’une déambulation avec un dispositif classique d’assistance comme la canne blanche.
Un environnement nouveau suppose des obstacles difficilement prévisibles (notamment ceux à hauteur de tête) et une trajectoire à préparer à l’avance. Cela a pour effet de demander une surcharge cognitive importante. Dans cette situation, une assistance numérique capable de capter l’environnement, de calculer une trajectoire et de fournir une information intuitive (information positive) sur la direction à suivre serait beaucoup plus simple à intégrer qu’une solution qui indique seulement les obstacles (information négative), comme c’est le cas des cannes blanches même celles dites « intelligentes ». L’information intuitive pourrait mimer les informations de forces et mouvements échangées entre guidant et guidé. Nous appelons ce type d’informations des informations kinesthésiques.
Notre expertise sur le sujet prend plusieurs formes :
– En tant que roboticien, nous avons noté que les technologies utilisées pour la détection d’obstacles et la planification de trajectoire pour les robots autonomes pourraient trouver un écho positif dans l’élaboration d’un dispositif d’assistance ;
– D’autre part, l’ISIR et ses activités spécifiques s’intéressent justement aux bonnes pratiques et à l’élaboration de nouveaux dispositifs permettant d’augmenter/substituer de l’information sensorielle dans différents cadres d’application (assistance/rééducation/chirurgie).
Les objectifs
Nous avions pour ambition de concevoir un dispositif d’une intuitivité optimale. Ainsi, le dispositif de l’équipe A-Eye a été créé avec une série d’objectifs convergents :
– exploiter le contexte offert par la compétition internationale du Cybathlon pour valider l’efficacité des retours sensoriels élaborés au sein de nos équipes,
– et tirer parti des compétences des étudiants de nos formations afin de mettre en évidence tout le potentiel de ces dernières.
Le dispositif se présente sous la forme d’un harnais/plastron sur lequel est fixé un système de retour kinesthésique (pantographe), avec une caméra 3D. Il possède aussi un ordinateur puissant permettant d’analyser/cartographier l’environnement avant de proposer une trajectoire permettant d’atteindre la position désirée tout en actualisant cette dernière en fonction de l’apparition de nouveaux obstacles. Le retour kinesthésique permet d’appliquer un effort dans deux directions (gauche/droite et avant/arrière), ce qui permet d’indiquer la direction à suivre de manière intuitive.
Ce dispositif représente une solution innovante à la frontière des technologies et des logiciels actuels développés en robotique, en traitement d’image, en intelligence artificielle et en communication haptique/kinesthésique.

Les résultats
Le dispositif développé à l’ISIR a atteint un niveau de maturité suffisant, permettant désormais une utilisation autonome par la pilote, avec la capacité de changer de mode en fonction des défis rencontrés.
Les séances d’entraînement hebdomadaires de la pilote, Salomé Nashed, malvoyante depuis sa naissance est chercheuse en biologie, permet d’affiner et de personnaliser le guidage pour s’adapter aux différentes épreuves du Cybathlon. Bien qu’elle qualifie le retour d’ « intuitif », il devient essentiel de l’éprouver auprès d’un plus large panel d’utilisateurs et utilisatrices afin de continuer à améliorer la solution et d’en renforcer les possibilités de personnalisation. Parallèlement, présenter le dispositif permettra de sensibiliser aux avancées technologiques actuelles, en montrant à la fois leur potentiel et leurs limites. Le partenariat avec l’INJA (Institut National des Jeunes Aveugles) Louis Braille permettra ainsi de présenter le dispositif aux élèves mais aussi aux instructeurs en mobilités.
La mission principale sera de rendre le dispositif existant open-source. Nous détaillons ici la démarche envisagée pour atteindre cet objectif :
– La documentation et la maintenance d’un GIT accessible en open source,
– Le bilan et l’optimisation des choix de matériaux et de quincailleries,
– L’élaboration de plans pour l’impression 3D et la découpe laser,
– La création de tutoriels vidéo,
– Tout le long du développement, nous recueillerons les retours des utilisateurs « techniques »:
(1) Prendre en compte les retours d’un groupe d’étudiants utilisateurs du fablab de Sorbonne Université qui auront à reproduire le dispositif à partir de la documentation disponible,
(2) Prendre en compte les retours des instructeurs en locomotion de l’INJA Louis Braille, premiers testeurs du dispositif en tant qu’équipe technique nouvellement formée. Leur rôle sera de s’approprier le dispositif et de proposer des personnalisations adapt.es aux utilisateurs, afin d’améliorer son ergonomie de mieux répondre aux besoins et aux difficultés spécifiques de chaque usager.
Au-delà de l’ouverture du dispositif actuel, le projet vise aussi à évaluer et développer des solutions plus en connections avec les personnes concernées. Ainsi des contacts ont été pris avec l’INJA Louis Braille pour avoir l’occasion de travaux d’innovations participatives. Ce projet s’effectue également avec le FabLab de Sorbonne Université. Ce projet sera par ailleurs l’occasion d’organiser des groupes de discussion et idéations entre les chercheurs-chercheuses, les étudiants-étudiantes de nos formations à Sorbonne Université, et des jeunes aveugles et personnes déficientes visuels. Ces animations seront portées par le projet pour développer des briques technologiques adaptés aux personnes concernées.
Partenariats et collaborations
L’équipe A-Eye a été fondé par Ludovic Saint-Bauzel et Fabien Vérité, chercheurs à l’ISIR et maîtres de conférences à Sorbonne Université. L’ingénieur en charge du projet est Axel Lansiaux, avec l’aide d’Aline Baudry et de Samuel Hadjes, ingénieur·e·s à l’ISIR. De nombreux étudiant·e·s des masters de Sorbonne université, des spécialités Main et ROB de l’école Polytech Sorbonne, ont participé au projet dans le cadre de leur projet de fin d’étude. Ce projet concerne aussi d’autres collègues à l’ISIR comme Nicolas Baskiotis et Olivier S. (Machine Learning), Nizar Ouarti (Perception) qui sont intéressés d’apporter leurs expertises à ce projet opensource.
Lien vers le site internet de l’équipe A-Eye : https://a-eye.isir.upmc.fr
Projet RODEO – Apprentissage profond robuste pour la robotique chirurgicale
Le projet ANR RODEO vise à transformer la robotique chirurgicale en intégrant les dernières avancées en intelligence artificielle (IA). Le cadre d’application est la chirurgie guidée par robot pour la colonne vertébrale, basée sur une plateforme chirurgicale disponible à l’ISIR.
Dans ce contexte, un bras robotique à 7 degrés de liberté (DoFs) est équipé de divers capteurs (position, vitesse, force, conductivité électrique, vibrations) et utilisé pendant des interventions chirurgicales, comme l’insertion de vis pédiculaires dans la colonne vertébrale. Cette plateforme robotique actuelle utilise un ensemble de lois de commande déjà implémentées (e.g., contrôle de position, de vitesse, de force) pour exécuter des tâches ou sous-tâches chirurgicales, comme le perçage d’une trajectoire préliminaire pour le placement des vis pédiculaires. Avant l’opération, un scanner 3D du patient est réalisé, permettant au chirurgien de définir la procédure médicale à suivre pendant la chirurgie.
Bien que des contrôleurs entièrement automatiques puissent être utilisés pour certaines sous-tâches sûres, les chirurgiens préfèrent un paradigme de co-manipulation pour les opérations sensibles, où les robots chirurgicaux assistent les procédures médicales. Dans ce cas, l’assistant robotique doit réagir fidèlement aux instructions du chirurgien tout en garantissant la sécurité du patient et du personnel médical, et s’adapter à l’environnement.
Le contexte
Bien que le système actuel de co-manipulation soit utile et réponde à certains besoins des chirurgiens, il peut être considérablement amélioré pour enrichir l’expérience chirurgicale. La plateforme chirurgicale de l’ISIR manque de modules de perception et d’enregistrement, et la procédure actuelle suppose que le patient ne bouge pas une fois positionné pour la chirurgie et que la colonne vertébrale est rigide. Cela peut rendre le transfert d’informations préopératoires complexe, imprécis et dangereux pour le patient. De plus, les contrôleurs actuels ne représentent pas certains phénomènes physiques complexes lors de la co-manipulation, comme les frottements du robot, les vibrations ou la compensation gravitationnelle, tous cruciaux pour des interventions chirurgicales précises.
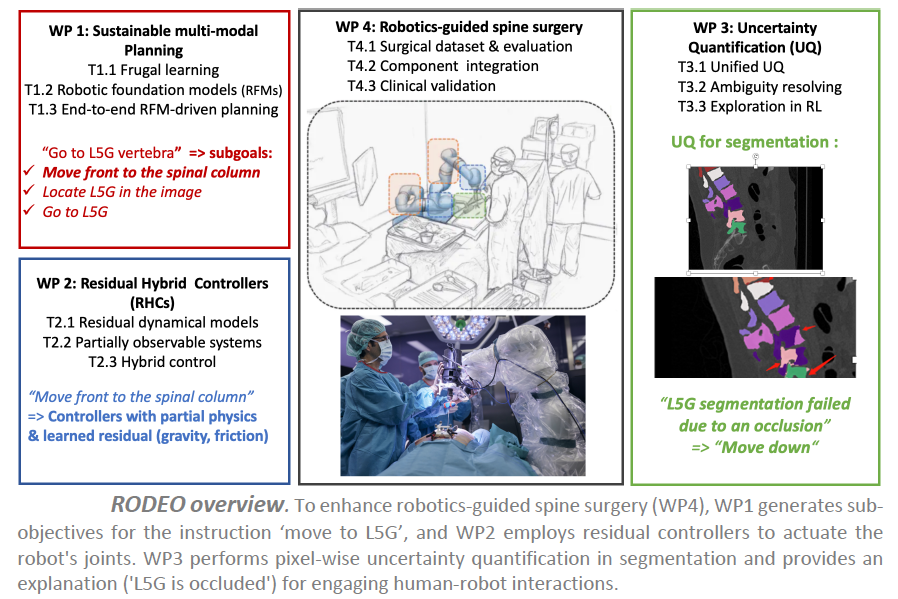
Les objectifs
Le projet RODEO vise à développer la prochaine génération d’IA génératives profondes pour surmonter les principaux défis mentionnés. L’objectif est de concevoir des systèmes d’IA avec une robustesse améliorée en termes de flexibilité et de fiabilité, tout en restant durables, ainsi que des modèles hybrides capables d’intégrer des connaissances physiques du monde.
L’hypothèse centrale de la recherche est que ces améliorations peuvent conduire à une avancée majeure dans la robotique chirurgicale. Des systèmes d’IA plus fiables peuvent améliorer leur acceptation par les experts médicaux et les patients, notamment en leur permettant d’évaluer leur propre confiance ou d’expliquer leurs décisions de manière compréhensible. Les modèles hybrides et durables pourraient considérablement améliorer le niveau d’automatisation dans la co-manipulation robot/chirurgien, réduisant ainsi la charge cognitive des chirurgiens et leur permettant de se concentrer entièrement sur les interventions médicales, ce qui améliorerait les procédures chirurgicales et les soins aux patients.
Les résultats
Dans notre cadre de test pour la chirurgie de la colonne vertébrale, nous attendons des améliorations majeures dans trois domaines principaux :
– concevoir des contrôleurs hybrides capables d’utiliser l’IA pour apprendre les composants résiduels des contrôleurs actuels difficiles à modéliser, tels que les frottements ou les vibrations ;
– augmenter la flexibilité du système avec des IA génératives profondes multimodales pour planifier à long terme en utilisant la perception visuelle et des méthodes basées sur l’IA pour enregistrer les scanners CT préopératoires avec les caméras de profondeur opératoires ;
– doter les systèmes d’IA de la capacité de quantifier leur propre confiance et d’expliquer leurs décisions à l’équipe chirurgicale de manière compréhensible.
Partenariat et collaboration
Le projet ANR RODEO est un projet mono-équipe mené par l’équipe projet MLR (Machine Learning and Robotics) de l’ISI, porté par Nicolas Thome, chercheur à l’ISIR et professeur à Sorbonne Université.
Projet « Intégration multi-sensorielle pour le maintien de l’équilibre »
Le contexte
Le maintien de l’équilibre nécessite l’intégration d’informations venant des différents systèmes sensoriels : visuels, vestibulaires, proprioceptifs et haptiques. Ces différents sens sont typiquement étudiés un par un, ce qui laisse ouverte la question de leur intégration. L’équipe IRIS de l’ISIR regroupe des experts et expertes sur le contrôle postural, l’haptique et l’adaptation visio-motrice.
Les objectifs
L’objectif est de combiner ces expertises pour étudier l’intégration multi-sensorielle pendant des perturbations de l’équilibre, en combinant des perturbations :
– mécaniques (via une plateforme de perturbation),
– visuelles (en réalité virtuelle),
– et haptiques (avec un dispositif de « light touch » et des dispositifs de stimulation haptique).
Partenariats et collaboration
Le projet « Intégration multi-sensorielle pour le maintien de l’équilibre » est un projet fédérateur, interne à l’ISIR, qui n’implique pas de collaboration extérieure au laboratoire.
