This project bridges machine learning and cognitive science to enable better collaboration between humans and robots. The overall goal of OSTENSIVE is to allow robots to perform tasks more effectively in collaboration with humans, by allowing improved communication and understanding between the two. By integrating the human perspective into perception, decision-making, and action generation, we aim to develop models capable of adapting to human mental states and behaviors.
In collaboration with Inria and LAAS, we intend to develop computational forward and inverse models that allow to integrate communication into action, from reasoning and planning to the execution of movements.

The context
When humans demonstrate a task, the demonstrations are directed not just towards the objects that are manipulated, but they are also accompanied by ostensive communicative cues such as gaze and/or modulations of the demonstrations in the space–time dimensions. These behaviors, such as pause, repetition and exaggeration, might appear to be sub-optimal, but they are provided by humans to communicate.
Cognitive Science addresses this challenge of communication in action by drawing inspiration from language (literal meaning – pragmatic inference). Most of the approaches of Human-Robot Interaction assume literal interpretation of behaviors resulting in a strong limitation of interpretation of actions and intentions of the other. There is a need for forward and inverse models being able to generate relevant content to the other (human/robot) and to adequately interpret the actions of the other.
Objectives
The aim of OSTENSIVE is to develop computational forward and inverse models using machine learning based approaches conditioned by reasoning mechanisms about humans. Our research ranges from the development of high-level models for reasoning and task planning to the implementation of low-level motion planning for precise physical execution.
Based on Cognitive Science based approaches, we will investigate situations, indicators and metrics allowing us to determine conditions under which humans engage and take benefit from such models by new approaches of real-time evaluation of second-person perspective taking. We will develop new models able to synthesize ostensive and interactive robot motions and probabilistic representations of ostensive actions learned from human demonstrations.
The results
We aim to adapt and extend experimental protocols used to study social cognition. Applications cover many sectors and include social navigation, and mobile manipulation in a shared environment, where we want to ensure that robots can navigate fluidly and perform tasks alongside humans in real-world scenarios, by integrating ostensive action into different robotics platforms.
OSTENSIVE’s work, carried out at several levels, aims to enable robots to correctly understand and interpret human intentions, to define explainable plans to accomplish tasks, and to perform actions in a readable manner for a human observer.
After ethical approval, we will conduct extensive experiments to validate the ostensive communication skills of the robots with naive participants that should maximally benefit from such skills to accomplish a task with the robot.
Partnerships and collaborations
OSTENSIVE is a collaborative initiative between ISIR, LAAS-CNRS, and INRIA to create a unified framework for human-robot interaction. ISIR is the coordinator of the OSTENSIVE project (ANR-24-CE33-6907-01).
ISIR – ACIDE Team
– Developing forward and inverse inference models, with works on understanding human intent and predicting how an agent’s actions will affect human perception.
– OSTENSIVE Lead : Mohamed Chetouani
INRIA (Nancy) – LARSEN Team
– Investigating ostensive motions at low-level, by leveraging tools such as control primitives and robotic policies.
– OSTENSIVE Lead : Serena Ivaldi
LAAS-CNRS (Toulouse) – RIS Team
– Developing socially aware planning methods, using Theory of Mind and perspective-taking.
– OSTENSIVE Lead : Rachid Alami
The study examined the emotions that listening to sounds produced by organic (i.e., real) affective tactile gestures (e.g., arm stroking, cheek caressing), presented in isolation, elicited in people not involved in the gestures. The study was motivated by the ever-increasing lack of engagement in interpersonal touch, in large part due to the digitalization of the human experience. This decrease in touch has been shown to have detrimental effects on individuals and deprives them (both touchers and touchees) of the numerous benefits of affective touch, including emotional regulation. As such, it becomes highly relevant to investigate alternative ways to convey the benefits of affective touch, such as through different tactile modalities. Here, sound is an interesting option given the close relationship between auditory and tactile waves.
The context
The study is part of the broad ANR MATCH project on Audio-Touch. It expands on the first study of said project by investigating the emotional responses to affective touch sounds beyond mere identification and by examining the influence of meaning and prior expectations about what affective touch sounds are like.
Objectives
The main objective of the study is to examine the emotional space of auditory cues produced by organic affective touch, in isolation, and the dimensions that influence it. Can these sounds evoke positive emotions? Are there variables that enhance these emotions? To this end, we conducted five experiments to disentangle the emotional responses to organic affective touch and the key variables that influence them.
Here, we extracted the auditory cues generated by organic affective tactile gestures, recruiting 14 romantically engaged couples and the tactile gestures they typically engage in, resulting in a wide variety of affective touch sounds. The objective of using organic gestures, rather than predefined recipe-like ones, was to more effectively evaluate the psychological processing of affective touch and its multisensory cues, and to capture its nuances.
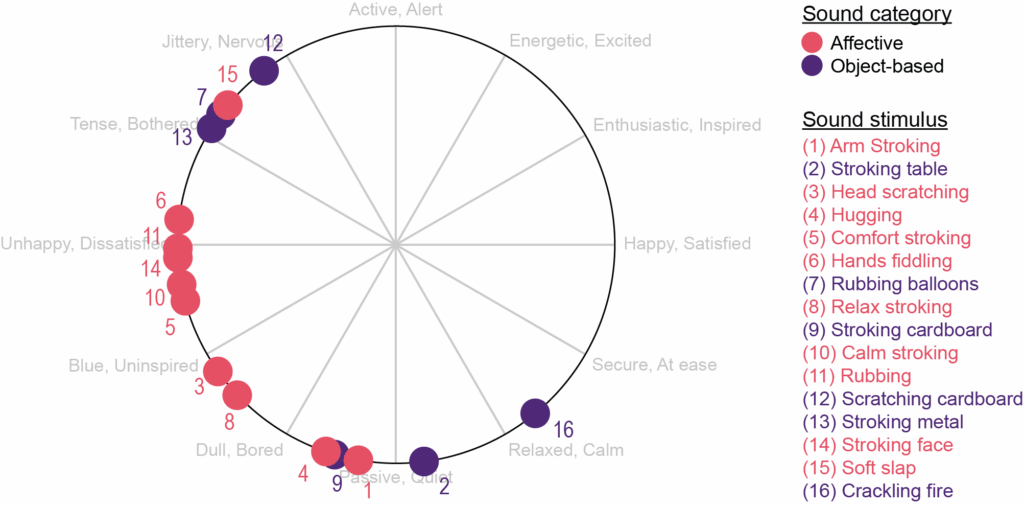
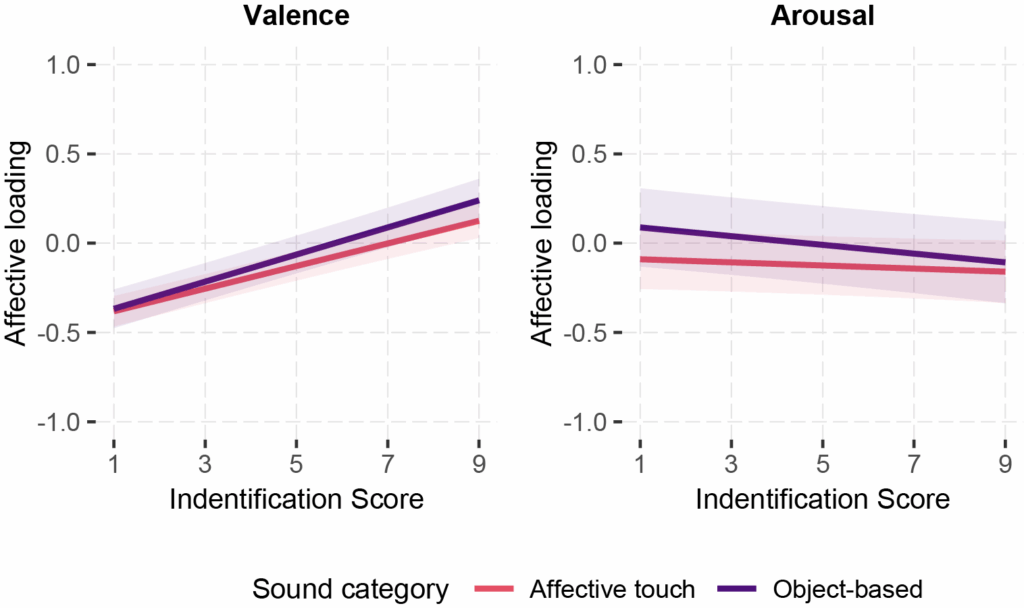
The results
Overall, we found that the sounds of affective touch alone elicited emotional responses with reduced positivity and marginally elevated arousal, and that individuals have a limited ability to identify affective touch in auditory cues. Importantly, we found that meaning matters. Explicitly framing the sounds as organic affective touch, rather than providing no context or framing them as object-based interactions, increases the valence they evoke. Furthermore, the more the sounds matched what individuals preliminarily expected affective touch sounds to be like, the higher the valence elicited by the sounds was, although people have limited knowledge and expectations of affective touch sounds. Our study is the first to examine the emotional space of the auditory dimension of affective touch, which, by itself, is a nascent field with intriguing opportunities.
From a practical perspective, our findings can be applied to enhance the emotional responses to non-tactile stimuli in the context of interpersonal interactions. For instance, imagine the narration of an emotional story that includes affective tactile interactions between the characters. The sounds of organic touch may be used to enhance the emotions the story aims to convey with these interactions. An additional possibility is the enhancement of the emotional responses to digital interactions with human and non-human agents (e.g., robots, anthropomorphized AI agents). However, it is important to note that more research on multisensory touch and its applications is needed.
Partnerships and collaborations
The study is part of the ANR Match project, in which we are collaborating with Catherine Pelachaud (ISIR), Ouriel Grynszpan (Paris-Saclay University), and Indira Thouvenin (UTC Compiègne). We also collaborated with the INSEAD-Sorbonne University Behavioural Lab, which supported us in recruiting the 14 couples and provided the physical facilities for recording the experimental stimuli.
The Haptivance project aims to create a new generation of tactile surfaces capable of producing sensations of force and movement under the finger. It arose from the observation that current haptic technologies on screens without physical buttons remain imprecise and do not provide true kinesthetic feedback, unlike very expensive robotic devices.
Building on Thomas Daunizeau’s thesis work at ISIR (with Sinan and Vincent Hayward) on acoustic metamaterials, the project aims to structure the propagation of vibrations to localise touch and generate directional sensations similar to physical keys/buttons on completely smooth surfaces.
The development of this technology represents a breakthrough for us in improving medical devices to make them intuitive and safe to use, while also facilitating cleaning and sterilisation by eliminating mechanical buttons that are difficult to clean and prone to the growth of microorganisms in hospital environments.
The context
Haptic feedback is now ubiquitous: smartphones, game consoles, industrial and medical interfaces. However, these systems only generate a general vibration that is impossible to locate precisely and cannot exert a net force on the finger. This severely limits their usefulness in situations where precision is critical: robotic surgery, automotive, accessibility devices. In these environments, users often have to look at the screen to confirm their actions, increasing cognitive load and the risk of error.
Hospital interfaces, for example, still rely heavily on mechanical buttons, which are difficult to sterilise and subject to wear and tear, whereas smooth touch surfaces are better suited to hygiene requirements. However, these screens lack sufficiently informative tactile feedback, forcing caregivers to visually check their actions, thus increasing cognitive load and the risk of error. Existing alternatives remain costly, complex or incompatible with screens. It is particularly in this context that there is a strong need for rich, localised touch that is compatible with interactive surfaces.

Objectives
The main objective of the project for the coming year is to develop a functional demonstrator of an interactive surface that produces localised and directional tactile feedback.
Scientifically, the project seeks to control the propagation of progressive ultrasonic waves on the surface using acoustic metamaterials. In other words, to be able to generate a net force on the finger without external actuation, but by making the surface resonate. To achieve this, we still need to understand the dimensions of our metamaterials in order to create a homogeneous force across the entire surface. We also need to study which haptic sensations will be most convincing in relation to a visual display and the position of the finger in real time.
The POC should enable users to feel buttons, edges, movements or guides on touchscreens. Ultimately, the project aims to develop industrialisable technology to provide a haptic solution for screen manufacturers.
The results
Initial experimental results have confirmed the possibility of generating progressive waves on a surface, creating a perceptible movement under the finger. The project must now extend and amplify this effect in a stable and efficient manner. The visuo-haptic demonstrator expected at the end of the project will enable multi-touch interactions: clicks, directional swipes, finger guidance, etc.
The main applications targeted are those in hospitals: surgical interfaces, monitors and imaging systems in the operating theatre, medical devices in intensive care, and robotic teleoperation interfaces.
In another context, certain situations also require a great deal of visual attention to the main task and are sensitive to distractions: this is the case with driving, where car dashboards consisting solely of touch screens could enable much safer interaction thanks to haptic feedback.
Overall, this technology aims to reduce the visual attention required for interface manipulation tasks by being easy to clean, improving the precision of gestures and enriching the user experience, including accessibility for people with disabilities.
Partnerships and collaborations
– Support programmes: PUI Alliance Sorbonne University – MyStartUp programme, i-PhD Bpifrance
– ISIR, CNRS Sciences Information Institute / CNRS Innovation for support with funding application
– SATT Lutech – Commercialisation, patents, maturation
– AP-HP – Innovation Hub & BOPEx third place, testing and co-design with healthcare personnel
Lexio Robotics is a software solution dedicated to robotic manipulation in diverse contexts, based on a genetic AI approach. It enables natural language reprogramming and autonomous skill acquisition for robots, overcoming current limitations in robotics and ushering in a new era for both B2C and B2B robotics. This start-up project was born at ISIR within the framework of a research collaboration on open-environment robotic learning. The team is currently exploring numerous high-potential use cases, ranging from manufacturing and logistics to services and domestic applications.

The context
The project addresses two major challenges:
Many sectors of the economy struggle to recruit for repetitive manipulation tasks. Manufacturing, logistics, hospitality, and personal care… many professionals are concerned about the sustainability of their activities, some of them being critical for the country’s sovereignty.
Robotics offers new opportunities to ensure continuity of production in these areas. However, despite recent advances, robots still lack true adaptive capabilities. In the spectacular videos shared online, robots are almost always teleoperated. The lack of solutions enabling robots to perform manipulation tasks with adaptive skills remains a major obstacle.
Recent advances in artificial intelligence offer promising avenues to overcome these barriers, generating excitement both in the academic world and in the industrial sector.
Objectives
This start-up project, strongly rooted in academic research, aims to equip robots with the ability to manipulate objects in open environments.
Specifically, it seeks to:
– Enable robots to quickly learn to perform new tasks reliably;
– Allow non-expert users to operate robots and reprogram them through natural language;
– Develop software solutions that comply with quality, ethical, and safety standards, enabling the deployment of robots in open environments for manipulation tasks.
The results
The potential applications span a wide range of sectors, from production (manufacturing, logistics) to services (hospitality, personal care).
The project builds on the state of the art in artificial intelligence for manipulation robotics, and in particular on a series of studies on genetic algorithms aimed at enabling easy reprogramming of robots.
These studies allow a robot to automatically learn new manipulation skills within a simulated scene representing a given operational environment.
The skills acquired — such as picking and placing objects, insertion, stacking, etc. — can then be successfully transferred to physical robots.
Furthermore, the data generated can serve as a resource to refine foundational models for new tasks.
Partnerships and collaborations
The scientific foundation of this project relies on several collaborations:
– The Franco-German project Learn2Grasp;
– The European excellence network for AI in robotics, euROBIN;
– The European open learning project, PILLAR;
– A collaboration with the Imperial College London.
The start-up aims to maintain strong ties with the academic community, notably with ISIR and Sorbonne University. Discussions are ongoing to define the scope of these collaborations.
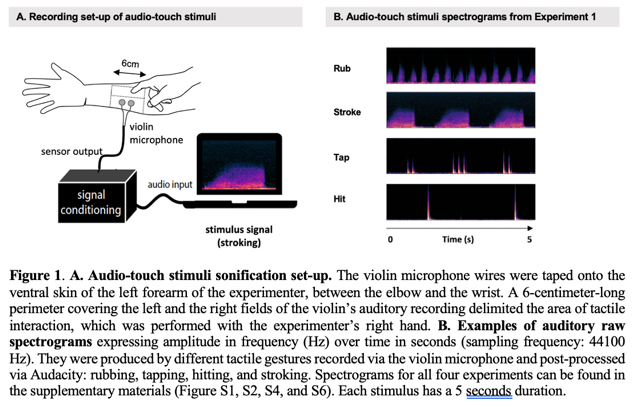
The Audio-touch project approach combines the results of research into social touch and the sonification of movement, making it possible to extract certain significant features from tactile interactions and convert them into sounds. In the project’s experimental studies, participants listening to skin-to-skin audio-touch stimuli accurately associated the sounds with specific gestures and consistently identified the socio-emotional intentions underlying the touches converted into sounds.
In addition, the same movements were recorded with inanimate objects, and further experiments revealed that participants’ perception was influenced by the surfaces involved in tactile interactions (skin or plastic). This audio-touch approach could be a springboard for providing access to the ineffable experience of social touch at a distance, with human or virtual agents.
The context
Touch is the first sensory modality to develop, and social touch has many beneficial effects on the psychological and physiological well-being of individuals. The lack of social touch accentuates feelings of isolation, anxiety and the need for social contact. Given this situation, there is an urgent need to explore ways of recreating the beneficial effects of emotional touch from a distance.
This project was born of this urgency, but also of a fundamental observation: touch and hearing share a common physical basis, that of vibrations. Sonification studies have already shown that it is possible to translate movements and their properties into sounds. It is therefore conceivable to translate certain characteristics of skin-to-skin interactions into perceptible auditory signals. The convergence of this need for a tactile link at a distance and the physical similarities between touch and sound has given rise to the Audio-touch project, which aims to transmit the information of affective touch via sound.
Objectives
The main objective of this research is to study the possibilities offered by audio-touch: can we convert skin-to-skin touch into sound? More specifically, the team then experimentally determined what social touch information the audio-touch stimuli could communicate to the people listening to them: can we recognise different types of touch gestures in our audio-touch stimuli? can we recognise different socio-affective intentions underlying these sonified touch gestures? does the surface on which the touch takes place (skin versus inanimate object) influence these perceptions?
The results
The four experiments conducted in this study show that social tactile gestures, their socio-emotional intentions and the surface touched (skin vs plastic) can be recognised solely from the audio-touch sounds created. The results show that :
– the participants correctly categorised the gestures (experiment 1),
– participants identified the emotions conveyed (experiment 2),
– their recognition was influenced by the surface on which the touch took place (experiments 3 and 4).
These results open up new perspectives at the intersection of the fields of haptics and acoustics, with the Audio-touch project situated precisely at the crossroads of these two fields, both in terms of its methodology for capturing tactile gestures and its interest in the human perception of sound signals derived from touch. They are also in line with research into human-computer interaction, and suggest that sounds derived from social touch could enrich multisensory experiences, particularly in interactions with virtual social agents.
Partnerships and collaborations
The project is a collaboration between :
– Alexandra de Lagarde, PhD student in the ACIDE team at ISIR,
– Catherine Pelachaud, CNRS research director in the ACIDE team at ISIR,
– Louise P. Kirsch, lecturer at Université Paris Cité, and former post-doctoral student in the Piros team at ISIR,
– Malika Auvray, CNRS research director in the ACIDE team at ISIR.
In addition, for the acoustic aspects of the project, the study benefited from the expertise of Sylvain Argentieri for the recordings and Mohamed Chetouani for the signal processing.
It is also part of the ANR MATCH programme, which explores the perception of touch in interactions with virtual agents, in partnership with HEUDIASYC (UTC) and LISN (Université Paris Saclay).
MAPTICS Project: Developing a Multisensory Framework for Haptics
The MAPTICS project that aims to develop a novel multimodal haptic framework by characterizing how users integrate multisensory cues into a unified perception and which facets of touch are the most essential to reproduce in virtual and digital applications.
To that end, it will investigate the potential of vibro-frictional rendering and multisensory reinforcement to create the illusion of 3D objects on the screen of a novel multimodal haptic interface and explore how haptics can be integrated in the next-generation of multisensory interfaces that combine high-fidelity tactile, auditory and visual feedback. Ultimately, this research it will enable the inception and evaluation of novel multimodal HCI applications for healthy and sensory impaired users.

The context
Current HCI interfaces commonly provide high-resolution visual and auditory feedback. On the opposite, haptic feedback is often absent from displays despite recent commercial products such as the Taptic engine on high-end Apple smartphones. Although multimodal interaction has the potential to enhance the acceptability, improve interaction efficiency, and be more inclusive for sensory impaired people, its development is hampered by the lack of multisensory framework for integrating haptic feedback with audio-visual signals, as well as by the low-fidelity of haptics in comparison to vision and audition in displays.
Consequently, the future of multisensory feedback faces the challenges of the design of high-fidelity haptic feedback and the efficient use of the cognitive principles underlying multisensory perception. In this context, novel rendering strategies and more capable devices integrating rich haptic feedback with the existing high-resolution audio-visual rendering are increasingly considered to optimize the feedback provided to users during their interaction with interfaces.
Objectives
– Develop a large interactive display capable of rendering vibrotactile and force-controlled haptic feedback alongside high-resolution audio-visual capabilities. The challenge will be to create an active touch interface are that provides richer feedback than the current state of the art scientific and commercial devices.
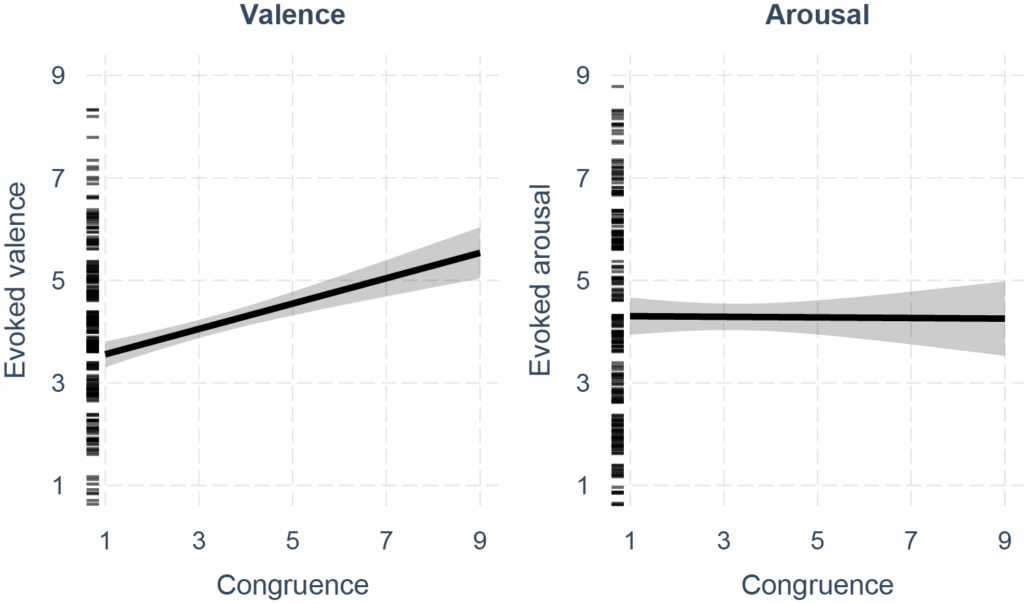
– Developing a realistic framework for multisensory rendering and use it to understand the cognitive processes at play when multisensory input is processed. For this goal, we will use the multisensory platform being developed in MAPTICS to manipulate the congruence between auditory, visual and tactile sensory inputs with the aim to investigate the multimodal reinforcement or disruption of cognitive representations.
– We will leverage the previous two subgoals to build a user interface with high-resolution multisensory reinforced haptic feedback. With this novel interface, we will study interactive scenarios related to the navigation in multisensory interactive maps or to the use of virtual buttons.
The results
Simultaneous vibrotactile stimulation and ultrasonic lubrication of the finger-surface interaction has not been studied yet even though it has the potential to lift serious limitations of current technology such as its inability of ultrasonic vibration to provide compelling feedback when the user gesture does not involve motion of the finger or the difficulty to create virtual shapes with mechanical vibrations.
Understanding better the joint implementation of both types of feedback will empower Haptic and HCI scientists in their research for more efficient and more compelling haptic devices. Also, vibrotactile and frictional haptic rendering are currently separate research topics.
After Maptics, we expect that haptic research will increasingly study these two complementary feedbacks in connection in order to efficiently develop more integrated rendering. In addition, the project will provide a new multisensory experimental tool that will enable a more advanced study and understanding of the underlying mechanisms of sensory integration.
Partnerships and collaborations
The MAPTICS project is an ANR (Agence nationale de la recherche) project, run in partnership with Betty Lemaire-Semail from the L2Ep laboratory at the University of Lille.
The project, “Robotic Learning for Mobile Manipulation and Social Interaction,” addresses the challenge of autonomous robots meeting complex needs, such as physical and social interactions in real-world environments. Current challenges include adaptability to unforeseen situations, smooth collaboration with humans, and the ability to navigate diverse settings. These issues are particularly critical in domains like domestic services, logistics, and agriculture.
The context
The ISIR context provides unique expertise in the multidisciplinary aspects of robotic learning, including control, machine learning, and social interaction. ISIR also provides access to advanced robotic platforms such as Tiago, Miroki, Pepper, and PR2, specifically designed for mobile manipulation. With these resources and its innovative approach, ISIR plays a pivotal role in developing autonomous robots capable of addressing societal and industrial challenges while strengthening collaborations within the European robotics community.

Objectives
The project aims to achieve a high level of autonomy for robots in complex environments. One of the primary goals is leveraging large language models (LLMs) for robotic planning, affordance identification, and object grasping, enabling better understanding and interaction with the real world. Additionally, the project seeks to develop an integrated system combining state-of-the-art perception models, particularly vision-based ones, and advanced control methods. For example, the QD-grasp (Quality-Diversity grasping) technique, developed at ISIR, is a cornerstone of this approach.
The overarching goal is to create robots that can interact autonomously, efficiently, and reliably with their environments while exploiting synergies between perception, control, and machine learning for applications across various domains.
The results
The project successfully integrated the QD-grasp stack on the Tiago robot, featuring advanced functionalities such as grasp generation, object detection, segmentation, and identification. Additionally, LLM-based planning was implemented, enabling the robot to understand and execute tasks expressed in natural language by human users. These developments significantly enhance human-robot interaction and the robot’s ability to operate in complex environments.
The project also participated in the annual euROBIN competition, showcasing advancements in the modularity and transferability of robotic skills. We continually share our developed components for mobile manipulation with the community, contributing to the collective evolution of robotic technologies and their application to real-world challenges.
Partnerships and collaborations
This project is an internal initiative of ISIR, leveraging expertise from various research and development areas. It particularly benefits from the contributions from:
– the ASIMOV team (on the manipulation and robotic interaction aspect),
– the ACIDE team (on cognition and interaction),
– and the Intelligent Systems Engineering priority.
These internal collaborations enable the mobilization of complementary skills in robotic learning, perception, control, and social interaction, thereby enhancing ISIR’s capacity to address major scientific and technological challenges.
Open A-Eye project: Kinesthetic feedback to guide the visually impaired
The originality of the A-Eye team’s device is that it provides kinaesthetic guidance that is more intuitive than the audio and/or vibrating feedback offered by commercial solutions. This reduces the cognitive load required to follow the information. This device, the fine-tuning of the feedback it provides and all the other solutions for meeting the various Cybathlon* challenges were co-designed with the help of our ‘pilot’. The A-Eye team places co-creation at the heart of the process, working with associations, accessibility experts and the blind A-Eye pilot. The aim is to create a solution that is ergonomic, accessible, easy to use and adapted to everyday life.
The A-Eye team’s device incorporates cutting-edge technologies, combining intuitive kinaesthetic feedback with computer vision and artificial intelligence functionalities. The wearable device, in the form of a harness/backpack, offers precise navigation, mimicking the interaction with a human guide and providing an intuitive experience.
*The Cybathlon is an event that takes place every 4 years and is organised by the Swiss Federal Institute of Technology in Zurich. It challenges teams from all over the world in 8 events. The aim is to demonstrate the technological advances that have been made in assisting people with disabilities to carry out everyday tasks
The context
It is well known that the least tiring guidance in a new environment is that provided by a person trained in guiding techniques. This guidance is much more intuitive and requires much less concentration than walking with a conventional assistance device such as a white cane.
A new environment involves obstacles that are difficult to predict (particularly those at head height) and a trajectory that has to be prepared in advance. This means a significant cognitive overload. In this situation, a digital assistance system capable of sensing the environment, calculating a trajectory and providing intuitive information (positive information) on the direction to follow would be much easier to integrate than a solution that only indicates obstacles (negative information), as is the case with white canes, even so-called ‘intelligent’ ones. Intuitive information could mimic the information about forces and movements exchanged between the guide and the guided. We call this type of information kinaesthetic information.
Our expertise in this area takes several forms.
– As a roboticist, we have noted that the technologies used for obstacle detection and trajectory planning for autonomous robots could find a positive echo in the development of an assistance device;
– On the other hand, ISIR and its specific activities are concerned precisely with good practice and the development of new devices for augmenting/substituting sensory information in different application contexts (assistance/rehabilitation/surgery).
Our objectives
Our ambition was to design a device that was as intuitive as possible. The A-Eye team’s device was therefore created with a series of converging objectives:
– to exploit the context offered by the international Cybathlon competition to validate the effectiveness of the sensory feedback developed within our teams,
– and to take advantage of the skills of the students on our courses to highlight their full potential.
The device takes the form of a harness/plastron to which a kinaesthetic feedback system (pantograph) is attached, with a 3D camera. It also has a powerful computer for analysing/mapping the environment before proposing a trajectory for reaching the desired position, updating it as new obstacles appear. The kinaesthetic feedback enables effort to be applied in two directions (left/right and forward/backward), providing an intuitive indication of the direction to follow.
This device represents an innovative solution at the frontier of current technologies and software developed in robotics, image processing, artificial intelligence and haptic/kinesthetic communication.

The results
The device developed at ISIR has reached a sufficient level of maturity, enabling it to be used autonomously by the pilot, with the ability to change mode according to the challenges encountered.
Weekly training sessions with the pilot, Salomé Nashed, who has been visually impaired since birth and is a biology researcher, enable the guidance system to be fine-tuned and personalised to suit the various Cybathlon events. Although she describes the feedback as ‘intuitive’, it is essential to test it with a wider range of users in order to continue to improve the solution and enhance its customisability. At the same time, presenting the system will raise awareness of current technological advances, demonstrating both their potential and their limitations. The partnership with the INJA (Institut National des Jeunes Aveugles) Louis Braille will provide an opportunity to present the system to students and mobility instructors.
The main task will be to make the existing system open-source. We detail here the approach envisaged to achieve this objective:
– Documentation and maintenance of an open-source GIT,
– Assessing and optimising the choice of materials and hardware,
– Drawing up plans for 3D printing and laser cutting,
– Creating video tutorials,
– Throughout the development process, we will be gathering feedback from ‘technical’ users:
(1) Take into account feedback from a group of student users from the Sorbonne University fablab, who will have to reproduce the device from the available documentation,
(2) Take into account feedback from the INJA Louis Braille locomotion instructors, who will be the first to test the device as a newly-formed technical team. Their role will be to get to grips with the device and propose customisations adapted to users, in order to improve its ergonomics and better respond to the specific needs and difficulties of each user.
As well as opening up the current system, the project also aims to evaluate and develop solutions that are more closely connected with the people concerned. Contacts have therefore been made with the INJA Louis Braille to give them the opportunity to work on participative innovations. This project is also being carried out with Sorbonne University’s FabLab. The project will also provide an opportunity to organise discussion groups and brainstorming sessions between researchers, Sorbonne University students and young blind and visually impaired people. These activities will be supported by the project to develop technological building blocks adapted to the people concerned.
Partnerships and collaborations
The A-Eye team was founded by Ludovic Saint-Bauzel and Fabien Vérité, researchers at ISIR and lecturers at Sorbonne University. The engineer in charge of the project is Axel Lansiaux, with the help of Aline Baudry and Samuel Hadjes, engineers at ISIR. A number of students from Sorbonne University’s masters programmes, and from the Main and ROB specialisms at Polytech Sorbonne, took part in the project as part of their end-of-study project. This project also involves other colleagues at ISIR, such as Nicolas Baskiotis and Olivier S. (Machine Learning) and Nizar Ouarti (Perception), who are interested in contributing their expertise to this opensource project.
Link to the A-Eye team website: https://a-eye.isir.upmc.fr
RODEO project – Robust deep learning for surgical robotics
The RODEO project is set to reshape surgical robotics by adapting cutting-edge AI. The practical testbed is robotics-guided spine surgery, based on a surgical platform available at ISIR.
In this setup, a 7 DoFs (degrees of freedom) robotic arm is equipped with various sensors (i.e. position, speed, force, electrical conductivity, vibrations) and is used during surgical intervention, e.g., pedicle screw insertion into the spine. This current robotic platform uses a set of already implemented control laws (e.g., position, speed, force control) to execute surgical tasks or subtasks, e.g., drilling a pretrajectory for pedicle screw placement. Before the operation, i.e., “pre-operative”, the patient undergoes a pre-operative 3D CT scan, such that the surgeon defines the medical procedure to follow during the surgery, i.e., “per-operative”.
Although fully automatic controllers can be deployed in safe sub-tasks, surgeons rather rely on the co-manipulation paradigm for sensitive operations, where surgical robots assist medical procedures. In this case, the robotic assistant is expected to faithfully react to the surgeon’s instructions while guaranteeing the safety of both patient and medical staff, and to adapt to the environment.
The context
While the current co-manipulation system [1] is helpful and meets some surgeons’ needs, they could be substantially improved to enhance the surgical experience. The ISIR surgical platform lacks perception and registration modules, and the current procedure assumes that once the patient is positioned for surgery, they does not move and that the spine is rigid. This can make the transfer of pre-operative information complex, imprecise, and dangerous for the patient. Additionally, current controllers fail to represent complex physical phenomena during co-manipulation, such as robot friction (difficult to model because the force applied by the surgeon is unknown beforehand), vibrations (critical for fine-grained manipulation such as peg in a hole), or gravity compensation (crucial for maintaining the robot in a steady position).
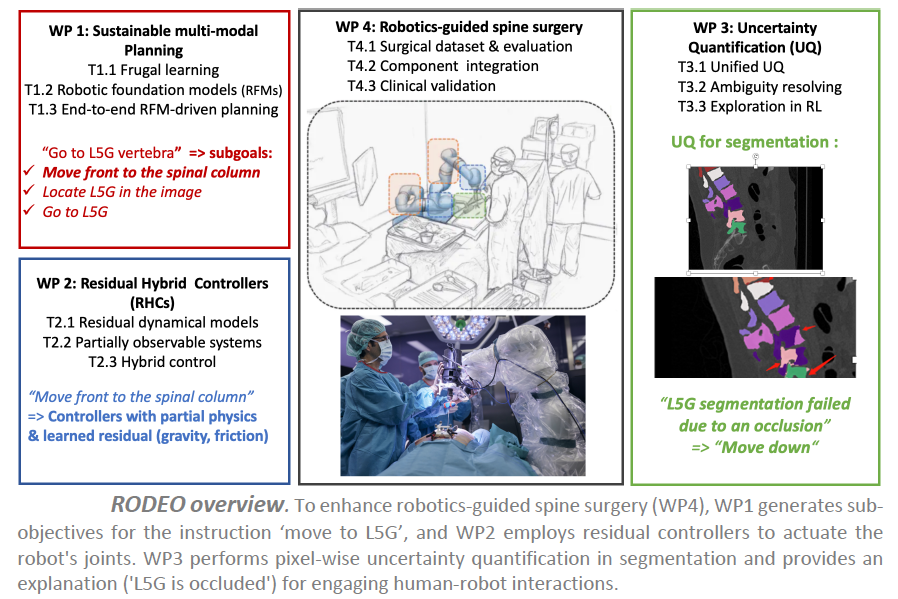
Objectives
RODEO aims to develop the next generation of deep generative AIs, which aims at overcoming the main challenges previously mentioned. The project especially aims at designing AI systems with enhanced robustness in terms of flexibility and reliability while remaining sustainable, and hybrid models able to incorporate physical knowledge of the world.
The central research hypothesis is that these improvements can lead to a major breakthrough in surgical robotics. In general, more reliable AI systems can substantially enhance their acceptance among medical experts and patients, especially by giving to AI systems the opportunity to assess their own confidence or explain their decisions in a human-understandable manner. Hybrid and sustainable models have the potential to substantially improve the level of automation in robot/surgeon co-manipulation. This holds the promise of reducing the cognitive load on surgeons, enabling them to concentrate entirely on medical interventions, ultimately elevating surgical procedures and patient care.
The results
In our spine surgery testbed, we expect major improvement at three main fronts:
– Firstly, we want to design hybrid controllers that can exploit AI to learn the residual components in current controllers that are difficult to model, such as friction, gravitation compensation or vibrations. The goal is to augment the level of automation of some tasks and to further assist in other tasks to release the surgeon’s mental load and enhance the accuracy and the safety of the surgical procedure.
– Secondly, we want to increase the flexibility of the system by using multi-modal deep generative AIs to tackle long-term planning based on language. It will include visual perception by developing AI-based methods for registering pre-operative CT-scans to per-operative depth cameras for enabling robust localization and control, e.g., for breathing compensation.
– Last but not least, we will endow AI systems with the ability to quantify their own confidence, and to explain their decision to the surgical team in an understandable manner, ultimately leading to rich human-robot interactions and dialogs.
Partnership and collaboration
The ANR RODEO project is a single-team project led by ISIR’s MLR (Machine Learning and Robotics) project team, headed by Nicolas Thome, a researcher at ISIR and professor at Sorbonne University.
Project “Multi-sensory integration to maintain balance”
The context
Maintaining balance requires the integration of information from different sensory systems: visual, vestibular, proprioceptive and haptic. These different senses are typically studied one by one, which leaves open the question of their integration. The IRIS team at ISIR brings together experts in postural control, haptics and visual-motor adaptation.
Objectives
The aim is to combine this expertise to study multi-sensory integration during balance perturbations, by combining perturbations that are :
– mechanical (via a perturbation platform),
– visual (in virtual reality)
– and haptic (with a ‘light touch’ device and haptic stimulation devices).
Partnerships and collaboration
The “Multi-sensory integration for balance maintenance” project is a federative project, internal to ISIR, which does not involve any collaboration outside the laboratory.
