
Les vertébrés sont capables d’apprendre à modifier leur comportement sur la base de récompenses et de punitions. Cet apprentissage, dit « par renforcement », est également l’objet de nombreuses recherches en Intelligence Artificielle pour augmenter l’autonomie décisionnelle des robots.
Comment apprendre par récompenses et punitions, le plus vite possible pour un coût de calcul minimal ? C’est à cette question que nous nous attelons en combinant des algorithmes d’apprentissage par renforcement aux caractéristiques complémentaires.
Ce projet interdisciplinaire vise à améliorer les performances des robots, mais également à mieux expliquer l’apprentissage chez les vertébrés.
Le contexte
L’apprentissage par renforcement distingue deux grandes familles d’algorithmes :
– ceux qui construisent un modèle du monde et raisonnent dessus pour décider quoi faire (MB ou model-based). Ils nécessitent beaucoup de calculs pour prendre une décision, mais sont très efficaces, apprennent à résoudre un problème avec peu d’essais et réapprennent tout aussi vite si la tâche à réaliser change.
– ceux sans modèles qui apprennent de simple associations état-action (MF ou model-free). Ils sont très peu coûteux en calcul, mais en contre-partie apprennent lentement et ré-apprennent encore moins vite.
Les vertébrés, eux, sont capables d’exhiber des comportement dirigés vers un but résultant de déductions sur la structure de l’environnement. En cas d’apprentissage prolongé, ils développent des habitudes qui sont difficiles à remettre en cause. Il est couramment accepté, depuis le milieu des années 2000 (Daw et al., 2005), que les algorithmes MB sont un bon modèle des comportements dirigés vers un but, et les algorithmes MF un bon modèle de la formation d’habitudes.
Les objectifs
Du point de vue de la robotique et de l’IA :
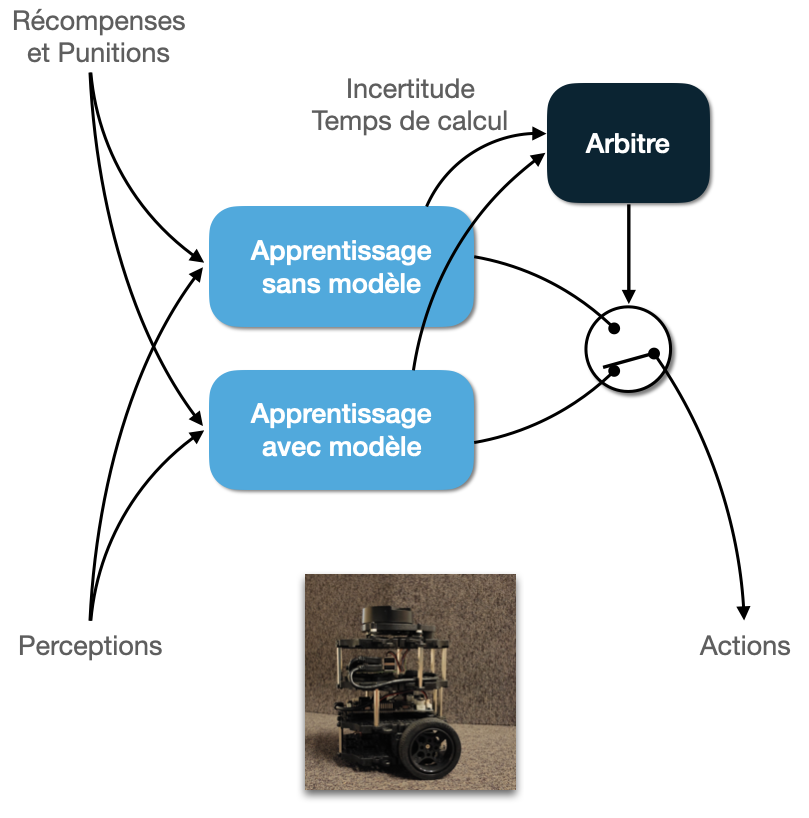
Nous cherchons à définir des méthodes de coordination de ces deux types d’algorithmes permettant de les combiner au mieux, afin d’apprendre rapidement et de s’adapter aux changement, tout en minimisant les calculs lorsque c’est possible. Nous testons nos réalisations dans des tâches de navigation robotique et de coopération homme-machine.
Du point de vue des neurosciences :
Nous cherchons plutôt à expliquer les interactions observées entre comportement flexibles et habituels, qui ne semblent pas nécessairement optimales. Cela implique que les méthodes de coordination développées pour la robotique et pour les neurosciences ne sont pas nécessairement identiques.
Les résultats
Nous avons initialement proposé une méthode de coordination des algorithmes MB-MF permettant d’expliquer des effets de compétition et de coopération entre systèmes d’apprentissage chez le rat (Dollé et al., 2010, 2018).
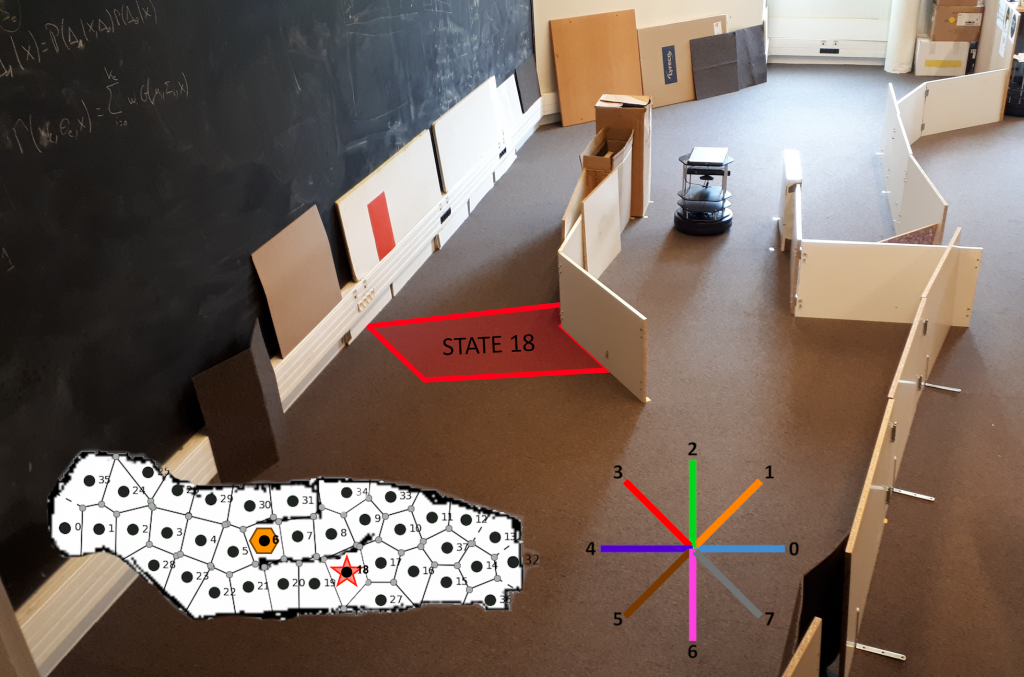
Elle a ensuite été adaptée pour son utilisation en navigation robotique (Caluwaerts et al., 2012), et dotée à l’occasion d’un système de détection de contexte permettant d’apprendre et de ré-apprendre rapidement en cas de changement de la tâche. Le développement d’un nouveau critère de coordination prenant en compte explicitement le temps de calcul a permis de proposer un nouveau système robotique ayant des performances maximales, identiques à celles d’un algorithme MB, pour un coût de calcul divisé par trois (Dromnelle et al., 2020a, 2020b).
En parallèle, des modèles ont été développés pour expliquer les décisions et les temps de réponse chez l’humain (Viejo et al., 2015) et le macaque (Viejo et al., 2018).
L’ensemble des réalisations de ce projet de fond ont été résumées dans l’article (en anglais) « Adaptive coordination of multiple learning strategies in brains and robots » (Khamassi, 2020).
Partenariats et collaborations
Ces travaux ont été menés dans le cadre de divers projets, financés entre autres par l’ANR (LU2, STGT, RoboErgoSum), la Ville de Paris (Emergence(s) HABOT), l’Observatoire B2V des mémoire, le CNRS, etc.
Ils s’appuient sur des collaborations entre :
– Andrea Brovelli, Institut de Neurosciences de la Timone (INT) de Marseille, en France,
– Raja Chatila, Benoît Girard et Mehdi Khamassi, Institut des Systèmes Intelligents et de Robotique (ISIR) de Paris, en France,
– Rachid Alami et Aurélie Clodic, Laboratoire d’analyse et d’architecture des systèmes (LAAS) de Toulouse, en France,
– Emmanuel Procyk, Stem cell and Brain Research Institute (SBRI) de Lyon, en France.




